.svg)


introduction
NVIDIA's Multi-Instance GPU (MIG) technology enables efficient resource utilization by dividing a single GPU into multiple independent instances. However, traditional GPU utilization monitoring is limited in MIG mode. This article presents GPU monitoring problems in MIG environments and solutions using DCGM_FI_PROF_GR_ENGINE_ACTIVE.
GPU utilization measurement limitations in MIG mode
According to official NVIDIA documentation, traditional GPU utilization metrics are not supported on GPUs with MIG mode enabled.

The NVIDIA MIG User Guide also specifies these restrictions:
“GPU utilization is not supported when MIG mode is enabled”

This is where the dilemma arises.
Real operating environment dilemmas
Let's consider the following scenario:
- 8 A100 GPUs installed on one node
- Chapter 4: Activate in MIG mode
- Use the remaining 4 chapters as standalone devices
How can I calculate the average GPU utilization of a node in such an environment? Since the 4 GPUs with MIG mode enabled are shown as N/A, should I exclude this and calculate with only 4 physical devices?
Solution: Use DCGM_FI_PROF_GR_ENGINE_ACTIVE
How to calculate utilization by MIG instance
There is a way to measure accurate GPU utilization even in MIG mode. immediately DCGM_FI_PROF_GR_ENGINE_ACTIVE It's about using metrics.
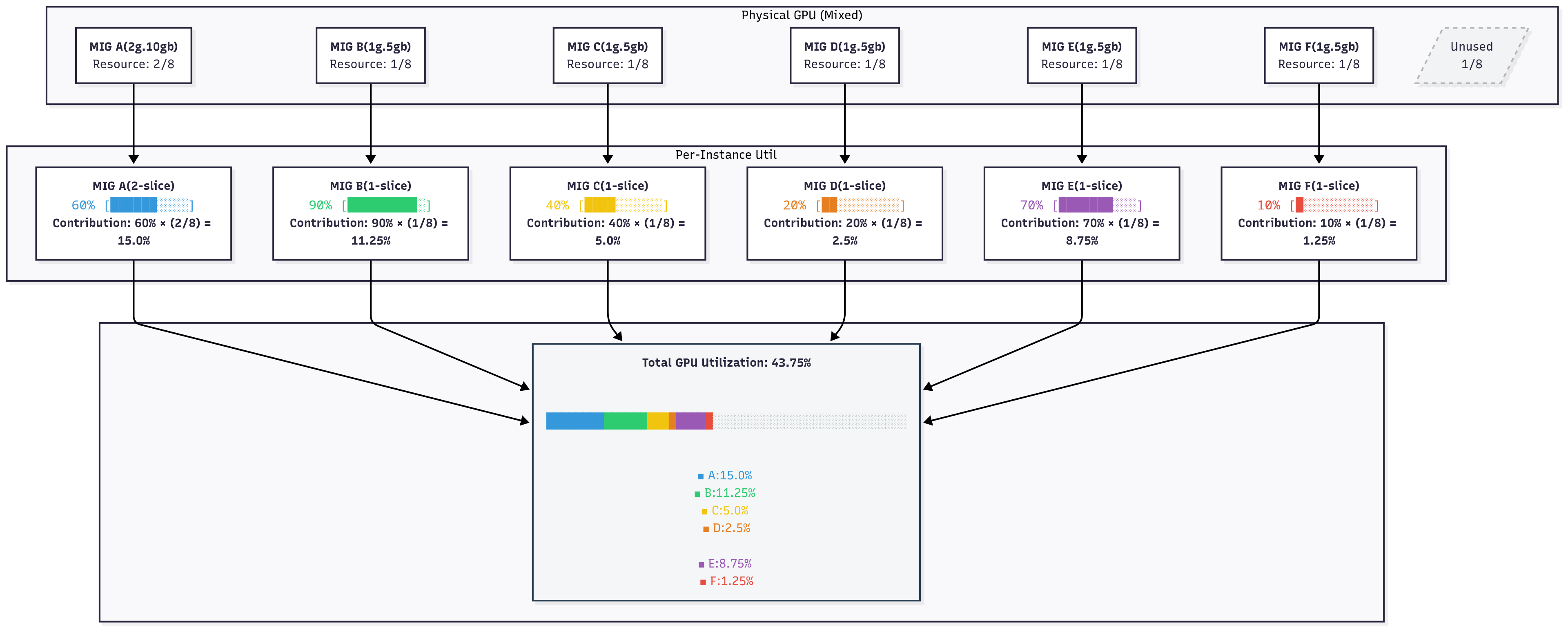
Calculation formula
Overall GPU utilization = σ (utilization rate of each MIG instance times the percentage of resources in that instance)
Example: MIG A (2g.10gb): 60% × (2/7) = 17.14% MIG B (1g.5gb): 90% × (1/7) = 12.86% MIG C (1g.5gb): 40% × (1/7) = 5.71% MIG D (1g.5gb): 20% × (1/7) = 2.86% MIG E (1g.5gb): 70% × (1/7) = 10.0% MIG F (1g.5gb): 10% × (1/7) = 1.43%
Total GPU utilization: 50%
This approach is based on a clear technical basis. Both the DCGM_FI_PROF_GR_ENGINE_ACTIVE metric selection and weighting methodology are based on NVIDIA's official documentation and recommendations.
I'll explain the rationale for using alternative metrics and calculation methodologies.
1. Rationale for using alternate metrics: NVIDIA GitHub official response
Source of evidence: NVIDIA DCGM GitHub Issue #64
Official response from NVIDIA developers:
“DCGM_FI_DEV_GPU_UTIL is equal to DCGM_FI_PROF_GR_ENGINE_ACTIVE. DCGM_FI_PROF_GR_ENGINE_ACTIVE is higher precision and works on MIG.”
This answer Why DCGM_FI_PROF_GR_ENGINE_ACTIVE can be used as an alternative indicator of GPU utilizationIt provides an official basis for
Features of GR_ENGINE_ACTIVE
- metric ID: DCGM_FI_PROF_GR_ENGINE_ACTIVE
- functions: Measuring NVIDIA GPU's Graphics Engine (GR Engine) activity level
- trait: Although it's called “Graphics” Engine, it actually handles both graphics and general computing workloads
- MIG compatibility: Accurate measurement is possible even in MIG mode
- precision: Provides higher precision than existing GPU_UTIL
2. Weighting method based on: NVIDIA DCGM official documentation
Source of evidence: NVIDIA DCGM- Understanding Metrics
Based on understanding the metrics presented in the NVIDIA DCGM official documentation Methodology for weighting and converting utilization per MIG instance to deviceIt can be derived.
Computational methodology
1) Basic calculation formula
2) Detailed calculation process
For each MIG instance:
Instance_Utilization = DCGM_FI_PROF_GR_ENGINE_ACTIVE(0.0 to 1.0)Slice_Ratio = Instance_Compute_Slices/Total_GPU_Compute_SlicesWeighted_Contribution = Instance_Utilization × Slice_Ratio
3) Actual calculation examples
On an A100 GPU (8 compute slices in total):

Total GPU usage = 0.1714 + 0.1286 + 0.0571 + 0.0286 + 0.1000 + 0.0143 = 0.5000 (50.0%)
4) Metric analysis (based on DCGM official documents)
- data range: 0.0 to 1.0 (ratio value)
- 0.0: GPU engine is completely idle
- 1.0: GPU engine is 100% utilized
5) Practical application considerations
- Can fluctuate instantaneously depending on the nature of the GPU workload
- Consider applying moving averages for stable monitoring (monitoring best practices)
Industry adoption status
- openCOST: GitHub PR #2853Used to calculate GPU costs for MIG environments
- Large GPU clusters: Adopted by cloud service providers' GPU monitoring solutions
corollary
GPU monitoring in MIG mode can be solved based on two key grounds:
- NVIDIA official response: DCGM_FI_PROF_GR_ENGINE_ACTIVE can be used as an alternative indicator for GPU_UTIL
- NVIDIA official documentation: Weight calculation methodology based on understanding metrics






