.svg)
.svg)



コンテナの世界は?
アプリケーションの展開におけるコンテナの登場は、明らかにソフトウェア開発と展開方法を革新的に変化させました。従来は、アプリケーションの依存関係、環境情報、ライブラリのバージョンなどにより、環境ごとに事前に考慮しなければならないことも多く、予測不能なエラーにより安定性を維持することが困難でした。しかし、コンテナの登場により、オペレータは複数の環境に拘束されることなく、必要な数の一貫した環境を構成でき、その間に展開中に発生したエラーを最小限に抑えることができました。
コンテナモニタリングの新しい視点
コンテナの登場で幸せになったのでしょうか? そうではないと思います。コンテナは、アプリケーションサービスに必要な最小限のもので構成される軽量パッケージです。そのため、必要に応じてコピーすることも、スケーリング作業も簡単ですが、規模が大きくなるほど管理ポイントも一緒に増加します。1回の作業が100個のコンテナへの配布である場合、または1000個のコンテナへのパッチである場合は、その後の状況を一度にモニタリングするのは簡単ではありません。このような状況では、多くのオペレーターが困難な部分が問題識別の難しさです。多くのコンテナを運営している状態で区間ごとに異なる問題が発生している場合、我々は効果的なロギングと分析方法を考える必要があります。
コンテナの過去/現在のイシューはログモニタリングで確認
今回は、私たちが備えていなかった過去のイシューをWhaTapのログモニタリングで降り返す方法についてお話しします。
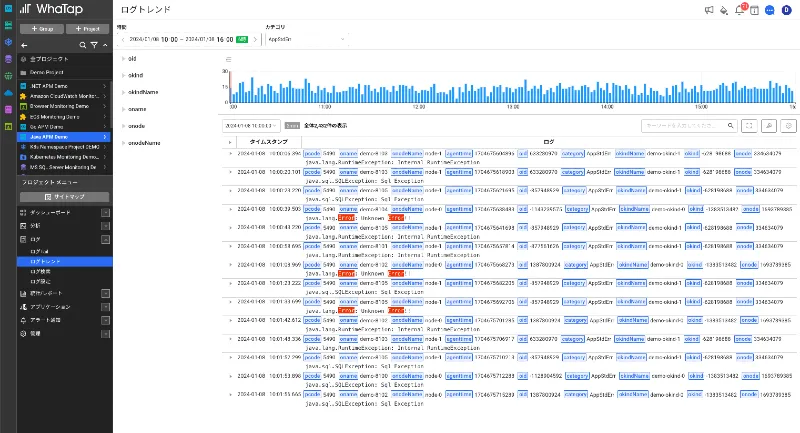
WhaTapは、モニタリング対象の業務単位と個々の識別情報に基づいて収集された様々なログを示します。たとえば、コンテナ単位、業務単位、サーバー単位で統合して表示することができ、各ログタイプによって発生した件数を棒グラフで視覚化し、収集されたログの量と推移を確認できます。リアルタイムの検索はもちろん、移動したい過去に戻り、未だ見つからなかった問題やバグを識別し、ユーザーの動作、トラフィックパターン、リソース使用率などの情報を得ることができます。さらに、セキュリティが重要視される最近のセキュリティログを含めて過去のログをモニタリングすることで、悪意のある活動を検出して保護措置を講じることができます。ログをよく見てみると、異常な活動、侵入試行、セキュリティ脅威に関連するログを確認してシステムの安全性を強化することも可能です。
すでに死んでいるコンテナログはどう確認できますか?
同様に、過去の時間に戻ると、現在は存在しないコンテナのログも再び照会できます。一般的に、OOM Killedなどのさまざまな要因のために消えてしまったコンテナのログを再確認するのは難しいかもしれません。コンテナ思想では、現在特定のコンテナに何らかの問題が生じたとき、これを今直すのではなく、’捨てて新しいものを作ろう’の傾向が強かったです。問題の状況をすばやく対処し、サービスの中断時間を短縮することができるというメリットがありますが、問題が発生したときにコンテナ内でどのような状況があったのかを遅く見てみるのはやや不便かもしれません。今はもう消えてしまったからです。このために、Elasticsearch、Logstash、Kibana(ELKスタック)、Grafanaなど別々に利用できるロギングおよびモニタリング関連のツールがありますが、WhaTabユーザーなら同じ機能をより便利に使用できます。
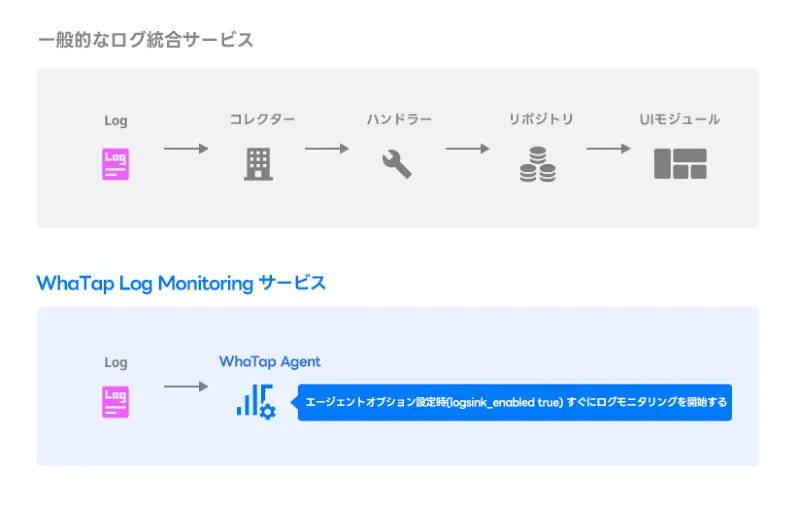
一般的なログ統合サービスは、コレクタ、ハンドラ、リポジトリ、およびUIモジュールで構成
されています。 段階的な設定と構成作業を必要とするために各モジュールを構築するプロセスは
面倒で、追加費用が発生します。 WhaTapログモニタリングは適用するのが簡単です。 既存の
モニタリングエージェントがコレクタとして機能するようにエージェントオプションをオンに
するだけで、ログモニタリングを開始できます。
WhaTapのログモニタリングを200%活用する様子を見せてください!
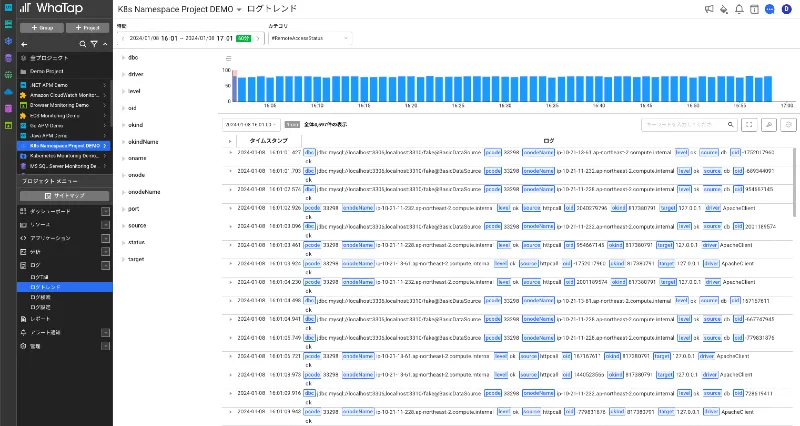
Kubernetes Monitoringを一緒に使用している場合は、複数の過去の時間に移動し、アプリケーションログとK8sイベントログを一緒に確認できます。アプリケーションログには、アプリケーション内部で発生したイベントとエラー情報が記録されます。Kubernetes イベントログは、クラスタの状態変更、Pod Scheduling、Nodeの問題などに関連するイベント情報を記録するため、これら2つのログタイプを一緒にモニタリングすることで、アプリケーションとクラスタで発生する問題をすばやく診断して解決できます。
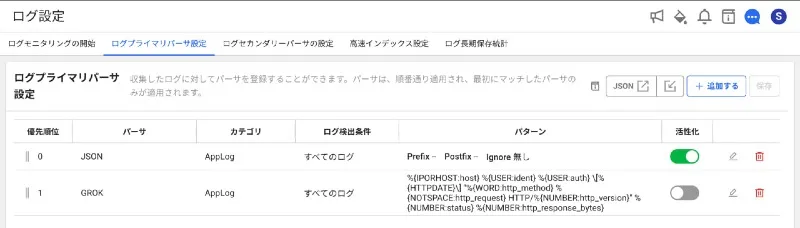
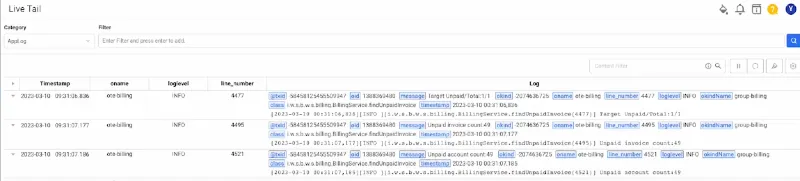
ログ解析を適用すると、不規則な形式であってもクエリを可能な形式でモニタリングできます。 ログを解析する方法は2つあります。
- GROKパーサー: 任意の形式で収集されるログを正規表現とGROK 文法を活用して解析します。
- JSONパーサー:JSON形式で収集されたログを解析します。
ログを解析すると、大量のデータをフィルタリングし、必要な情報だけを抽出できます。 これにより、複雑なログデータから重要な情報のみをスクリーニングしてモニタリングおよび分析することができ、大量の情報のオーバーロードを防ぎ、有用なデータに集中することができます。
一緒に見ると良いポスト




