.svg)


GPUが溶けている – AIブームとインフラ警告
2025年3月、OpenAIが「ChatGPT」で提供開始した新たなAI画像生成機能が大きな人気を集めており、最高経営責任者(CEO)のサム・アルトマン氏は「GPUが溶けている」とソーシャルメディア「X」に投稿した。
"It's super fun seeing people love images in ChatGPT, but our GPUs are melting."
ジブリスタイルの画像生成機能が爆発的な人気を得ていた時点で、急激に増加したリクエスト量によりサーバーが過負荷になった状況をユーモラスに表現した文章だった。しかし、この発言は単なる冗談ではなかった。OpenAIは実際にGPUの過負荷を防ぐために一時的な使用制限措置を導入し、全世界のユーザーが機能の使用に制約を受けた。
この事例はAIインフラ運用の新しい現実を示しています。AI時代の重要な資産であるGPUは、もはや単なる高性能計算機器ではなく、ビジネスの継続性と運用効率を左右する戦略的インフラとしての地位を確立しつつあります。そのため、GPUを持続的に監視することは企業の生存において必須の課題となりました。
GPUモニタリングが必要な理由
沢山のGPUを保有しているだけでは不十分です。大事なのは、GPUをどれだけ活用しているかを定量的に測定し、管理する能力です。次は、GPUモニタリングが必要な7つの理由です。
1. GPUは高価な資産であり、モニタリングしなければ損失が発生します。
GPUはAIインフラにおいてコストが高い構成要素の一つです。実際の運用現場では、GPUが過剰に割り当てられたり、アイドル状態に放置されたりするケースが頻繁に発生します。使用率、待ち時間、プロセス占有率を持続的に追跡しないと不要なコストが蓄積され、投資対効果(ROI)が下がります。
2. GPUはCPUより寿命が短く、故障の確率が高いです。
GPUは高温、高負荷環境で動作するため、温度の上昇、電力過負荷、メモリリークなどによる故障が事前の警告なしに発生する可能性があります。温度、電力、メモリ使用パターンをリアルタイムに監視することで、異常兆候を早期に検知し、障害を予防することができます。
3. AIワークロードはGPUリソースを非効率的に使用する可能性があります。
AIモデルの学習(ジョブ)と推論(インファレンス)作業ではGPUコア、メモリ、帯域幅などのリソースの消費が異なります。しかし、運用環境では静的割り当て方式のため、リソースの浪費やボトルネックが頻発します。GPU単位の詳細指標を分析することで、ワークロードの特性に合わせたリソース配分戦略が策定でき、速度とコストの両方を最適化できます。
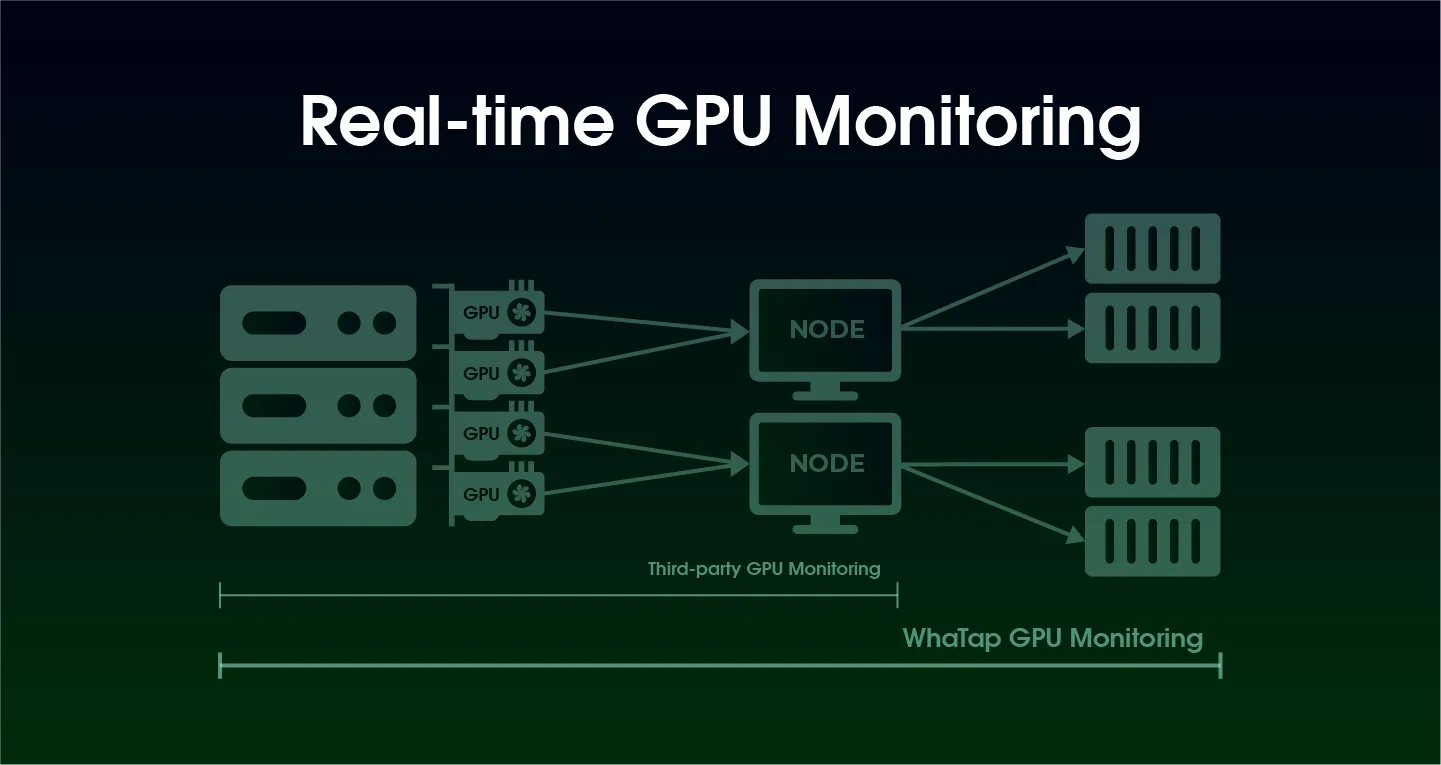
4. Kubernetes環境でのAI運用にはGPUの可視性が不可欠です。
多くの企業がAIインフラをKubernetesクラスターで運用していますが、基本的なモニタリングツールはCPUとメモリ中心であり、GPU指標の提供は限られています。GPUがどのノードに配置されているか、Pod単位でどのように使われているかが確認できないと、リソースのボトルネックや障害時に早急な対応が難しくなります。WhaTapのGPUモニタリングは、Kubernetes環境に最適化されたダッシュボードを提供し、GPUの状態をリアルタイムで可視化します。
5. GPUモニタリングは戦略的インフラ運用のスタートラインです。
GPUモニタリングは単なる状態チェックではなく、リソース活用の最大化、予測に基づく運用、コスト最適化のための戦略的ツールです。蓄積されたGPUデータは、拡張時期の予測、自動スケーリングポリシーの策定、FinOps/AIOpsの実行のための重要な根拠となります。特に、GPUモニタリングに基づくキャパシティプランニングは、オーバープロビジョニングを防ぎながら、安定性と拡張性が同時に確保できます。
6. GPUの障害はビジネスの障害につながります。
画像生成、音声分析、リアルタイム翻訳など多くのAIサービスはGPUを核心的な計算リソースとして使用しています。GPUの障害は性能の低下を超えて、品質の低下、全体サービスの中断につながることがあります。
SLA(サービスレベルアグリーメント)が重要なB2B環境では、GPUの異常がリアルタイムで検知できない場合、可用性の低下、顧客の離脱、SLA違反による金銭的損失が発生する可能性があります。
Gartnerのレポートによると、ITインフラの障害による平均損失は1分あたり5,600ドル(約75万円)、1時間あたり330万~400万円に達します。GPUの障害もこれに含まれます。
7. GPUモニタリングはAIインフラのオブザーバビリティの重要な要素です。
オブザーバビリティとは、システムの状態を多次元的に収集、分析し、原因と結果を関連付ける能力です。
AIインフラにおいてGPUは単一のリソースであり、性能の低下、ボトルネック、リソースのミスマッチの主要な原因です。GPUの状態を他の指標と関連付けなければ、根本原因分析が困難になります。
例えば、GPUメモリのボトルネックは推論速度を遅くし、これはAPIの応答遅延やユーザーエクスペリエンスの低下につながることがあります。
そのため、GPUモニタリングはエンドツーエンドのオブザーバビリティシステムの必須要素です。
終わりに: GPUモニタリングは必須です
AI時代においてGPUは企業成長の重要な原動力である同時に、適切に管理しなければ大きなコストを発生させるリスク要因でもあります。GPUモニタリングは単なる使用量の確認を超え、コスト削減、障害予防、インフラ戦略の策定に役立ちます。
安定、かつ快適な運用のために、GPUモニタリングは必須であり、今こそがGPUをリアルタイムでチェックし、体系的に運用する時です。