.svg)
.svg)


はじめに
私がWhaTapに入社してから4ヶ月ほどなりました。これまで、既存のコードを修正したり、新機能を追加しながら経験したことの中で、パフォーマンスに関するトピックでまとめてみました。実際のコードをすべて移動するのは難しく、状況の説明が少し不足する可能性があります。このポストがパフォーマンスの最適化の基本的な理解のためにお役に立てたらと願っています。
Interlockedを活用する
マルチスレッドの状況でしばしば発生する並行性の問題を解決するために、通常ロックを使用します。ロックの使用は正しく管理されない場合には性能低下を引き起こす可能性があります。特に、ロックがかかっている状態で実行時間が長くなると、これは性能に致命的な影響を及ぼす可能性がある。
レガシーコードでは、Finish() メソッド(Method)の動作を保証するためにロックを使用しました。IsFinishedというブール変数を変更する前にロックをチェックし、すでにIsFinishedがtrueの場合はメソッドの実行を停止します。これにより、マルチスレッドの状況でFinish()メソッドが重複して実行されるのを防ぐことができますが、ロックの使用によるパフォーマンスの低下が懸念されます。
private bool IsFinished = false;public void Finish(DateTimeOffset finishTimestamp){lock (_lock){if (!IsFinished){// ...IsFinished = true;}}}
この問題を解決するために Interlocked クラスを利用する方法を紹介します。Interlocked クラスのメソッドは、アトミック操作を提供してスレッドの安全性を保証し、同時にロックを使用しないため、パフォーマンスの低下を最小限に抑えるという利点があります。Javaでは、Atomicは同じ機能を提供します。
次のコードでは、Interlocked.Exchange() メソッドを使用して IsFinished 値を 1 に変更し、古い値を返します。 戻り値が 0 でない場合は、すでに一度変更された状態なので、前のコードと同じ意味を持ちます。これにより、既存のロックを使用しなければならなかった部分をロックなしで原子的に処理することができ、パフォーマンスの向上に役立ちます。
private int IsFinished = 0;public void Finish(DateTimeOffset finishTimestamp){if (Interlocked.Exchange(ref IsFinished, 1) != 0) return;// ...}
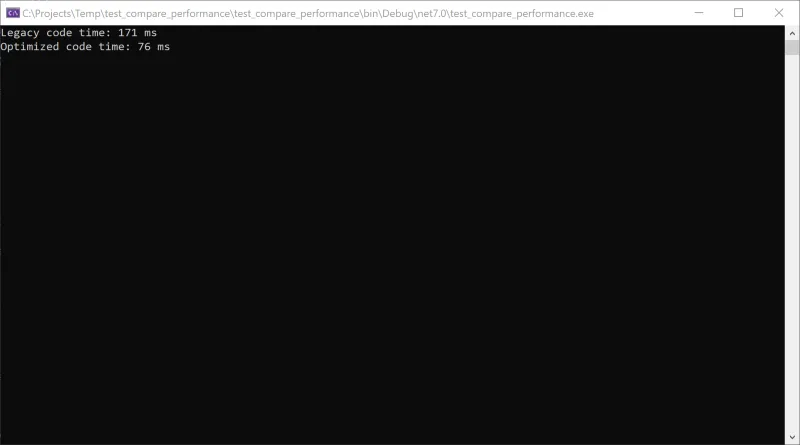
以下のスクリーンショットは、2つのコードの実行時間を比較したものです。状況によっては、より極端な違いが見られる場合があります。
InterlockedQueue
今回は、もう少し複雑な状況でInterlockedを適用する方法について学びましょう。
InterlockedQueue は、特別な状況で設計されたキューの実装クラスです。 APM開発には注意することがあります。その中でも、APMプログラムが顧客の性能と安定性に影響しやすい構造である点です。したがって、性能と安定性に留意し、開発に集中しています。以下は、ネット(.NET)でアクティブスタックを適用するためにプロセスでさまざまな試みを行ったいくつかの内容です。
定期的に発生するトランザクション情報をキューに入れ、スタックをダンプするスレッドが定期的に処理する必要がある状況です。典型的な生産者 - 消費者(Producer-consumer)パターンです。ConcurrentQueueを利用して簡単に処理することもできますが、ロックによるコンテキストスイッチングコストが懸念され、Interlockedを利用して新しいキューを作成してテストしてみました。
WhaTapのアクティブスタックとは? ワタップのアクティブスタック機能は、実行中のトランザクションのスタック情報を収集する機能です。 スタック情報は10秒ごとに収集され、収集されたデータは統計で確認できます。 統計情報は、長時間実行されるメソッド、短時間で実行されますが、頻繁に頻繁に実行されるメソッドの両方を比率で識別できます。 症状の再現なしに障害の根本原因を分析したり、Core library欠陥などの困難な問題の原因も把握することができます。
[アクティブスタックの詳細]
using System;using System.Threading;using System.Collections.Generic;namespace WhaTap.Trace.Utils{class Node{public Node(T value){Value = value;}public T Value;public Node Previous = null;}public class InterlockedQueue{public bool Enqueue(T value){var newNode = new Node(value);var tail = _tail;newNode.Previous = tail;var previous = Interlocked.CompareExchange(ref _tail, newNode, tail);return previous == newNode.Previous;}public bool TryEnqueue(T value, int tryCount){while (tryCount-- > 0){if (Enqueue(value)) return true;}return false;}public List Get(){var list = new List();var stack = new Stack();var tail = Interlocked.Exchange(ref _tail, null);while (tail != null){stack.Push(tail.Value);tail = tail.Previous;}while (stack.Count > 0){list.Add(stack.Pop());}return list;}private Node _tail = null;}}
Enqueueが失敗する可能性があるアルゴリズムなので、成功するまで何度も試すメソッドも追加しました。アクティブスタックは一部欠落しても大きく問題になることがなく、最大8回程度まで繰り返すようにしましたが、デモテストの状況ではほとんど失敗は起こりませんでした。そして、ConcurrentQueueとは異なり、これまで積み重ねたデータをGetからリストに一度にインポートする点が異なります。
テスト結果は、CPU 100%のデモプログラムが実行されている状況でInterlockedQueueを適用すると、40%未満に低下しました。デモプログラムの他の機能によって、2つのキュークラスのパフォーマンスの違いを正確に測定したわけではありませんが、意味のある数値でした。
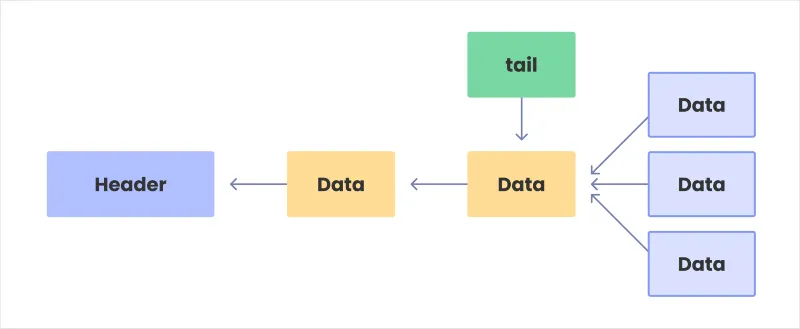
InterlockedQueueはLinked list構造になっています。末尾に対応する指標は_tail変数に格納されます。新しいデータを追加するときは、_tailに対応するデータの後に貼り付けてください。このとき、他の下の図のように他のスレッドが一緒に競合すると、複数のデータが尾につながりますが、_tailが自分を指すようにする過程でInterlockedを使用するため、結果的に1つのデータだけを尾付けに成功することになります 。
InterlockedRingBuffer
ソフトウェア開発がいつものように、追加的な要件を遅く知ることになりました。スタックダンプがパフォーマンスに影響を与えるのを最小限に抑えるために、一定数未満の情報だけをキャプチャして分析する必要があることがわかりました。そこで今回はInterlockedQueueよりもさらに改善されたInterlockedRingBufferを作成して適用してみました。
using System;using System.Threading;using System.Collections.Generic;public class InterlockedRingBuffer<T>{public InterlockedRingBuffer(int capacity){Capacity = capacity;tail = 0;buffer = new T[Capacity];}public void Enqueue(T value){var index = Interlocked.Increment(ref tail);buffer[index % Capacity] = value;if (index > Capacity){Interlocked.CompareExchange(ref tail, index % Capacity, index);}}public void Iterate(Action<T> action){int currentTail = tail + (Capacity - 1);currentTail %= Capacity;for (int i = 0; i < Capacity; i++){action(buffer[currentTail % Capacity]);currentTail++;}}public void Iterate(Func<T, bool> action){int currentTail = tail + (Capacity - 1);currentTail %= Capacity;for (int i = 0; i < Capacity; i++){if (action(buffer[currentTail % Capacity])) break;currentTail++;}}public int Capacity { get; private set; }private readonly T[] buffer;private int tail;}
最近のデータだけをインポートすれば良いので、バッファがプールされた状態で新しいデータが入ってくると、最も古いデータを上書きする構造です。キューに積み込む際に失敗を考慮する必要がなくなり、少しですが性能向上もありました。
var index = Interlocked.Increment(ref tail);
InterLockedを利用してインデックスを一つずつ積み上げていきながらキューにデータを入れるので、マルチスレッドの状況でも衝突は起こりません。indexがバッファのサイズを超えた場合は、最初から再開するために%演算子を使用しています。
buffer[index % Capacity] = value;
Capacityのデータタイプが符号なしで最大サイズがCapacityで割られている場合は問題ありませんが、そうでない場合は定期的にテールの値を調整する必要があります。この時もスレッドセーフを念頭に置かなければなりません。以下のコードはマルチスレッドの状況でも安全に動作します。
CompareExchange() は、tail の値が index と等しくないと動作しなくなります。 他のスレッドが途中で挟まれてテール値が変更された場合、動作しないため衝突しなくなります。
if (index > Capacity){Interlocked.CompareExchange(ref tail, index % Capacity, index);}
使用例のコードは次のとおりです。
int count = 0;_steps.Iterate((step) =>{try{if (step.IsFinished) return false;count++;if (count > Settings.Instance.ActiveStackCount) return true;captureCallStack(step);}catch (Exception e){WhaTapLogs.Error($"Failed to capture call stack: {e.Message}");return true;}// Iteration will stop when return true.return false;});
おわりに
このポストでは、パフォーマンスの最適化に関するいくつかの戦略と実際のコードを見てみました。1編ではInterlockedを活用したキューとバッファの実装などを取り上げてみました。続きの2編では、他のさまざまな方法でパフォーマンスを向上させる方法について学びましょう。
もう1つのアドバイスをしますと、パフォーマンスの最適化には常にトレードオフがあり、すべての状況に適した「完璧な」方法はありません。したがって、開発者は常に特定の状況と要件を考慮して適切な最適化戦略を選択する必要があります。このポストがそのような決定にお役に立てたらと思います。




