.svg)

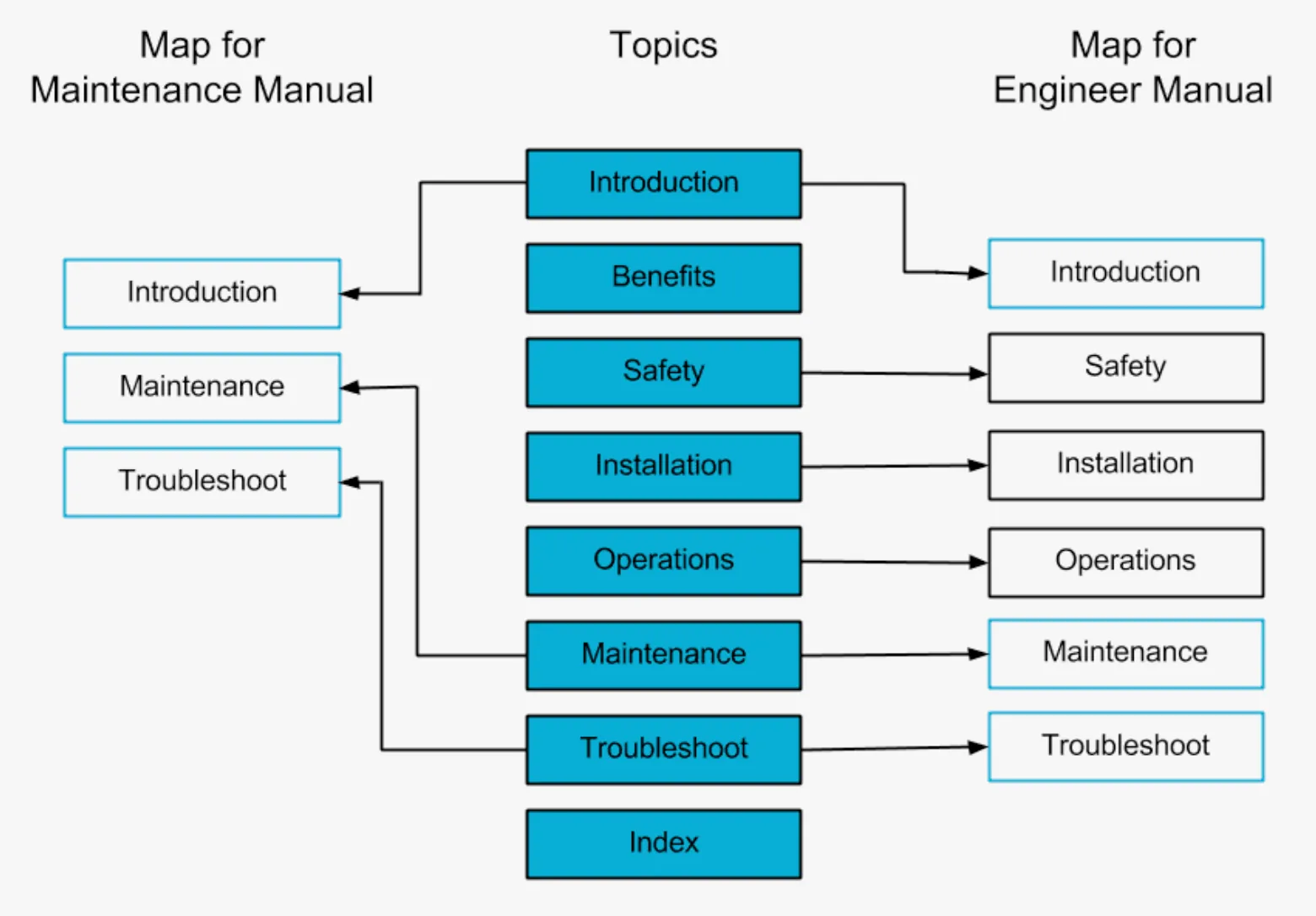
Before you begin
User guides have traditionally been created in an XML environment in the Anglo-American region, and in Korea they have been produced using editing tools such as InDesign.
In an environment where user guides are created in XML DITAIt is possible to filter content through an open source called.
Multiple topics can be organized into a single table of contents, and the output results can be different according to specific conditions entered in the XML. For this reason, the technical writing culture in the XML environment is well established in the Anglo-American region.
However, in Korea, mainly printing environments, user guides have been produced in InDesign, Express, or MS-Word environments since the beginning. Many manual companies still use graphic editing tools to create manuals. Of course, there are recent changes to XML environments.
In an XML environment, the user guide DITAUse to filter content. Writing documents using XML is difficult to learn, and conversion to other formats requires XSL logic.
Editing tools like InDesign don't have the same way you can reuse documents in the same way as XML. Therefore, it is inconvenient that you have to copy and paste the same content, and if you want to edit the same content, you have to repeat and edit all documents containing that content.
Recently, the number of examples for making the final output of user guides in HTML format is increasing and becoming more common. There is a trend where even large companies produce printed materials with a focus on legally required content, and produce user guides with various and extensive content in HTML format, or create and distribute the created HTML files as applications. Also, IT companies do not dare to print user guides and technical documents for their solution products, and produce and distribute user guides in HTML format as the number of products in the SaaS environment increases.
WTAP's monitoring solution also creates and distributes user guides in HTML format in line with this trend. Documents are generated in markdown format, and the final output is HTML generated using the Static Site Generator (SSG) open source software engine. There are many open sources for SSG, but Watap is currently DocusaurusI'm using You can use MDX documents that are optimized for React environments and extend markdown documents. It has the advantage of dividing documents by topic and being able to load and reuse them individually.
The Watap technical writer team has been developing and utilizing React components on Docusaurus to create and manage documents efficiently.
Reusing documents
Docusaurus allows you to reuse MDX files like components.
<!-- _markdown-partial-example.mdx -->
<span>Hello {props.name}</span>
This is text some content from `_markdown-partial-example.mdx`. <!-- someOtherDoc.mdx -->
import PartialExample from '. /_markdown-partial-example.mdx ';
<PartialExample name="Sebastien" />

This way, you can reuse the same content across multiple products.
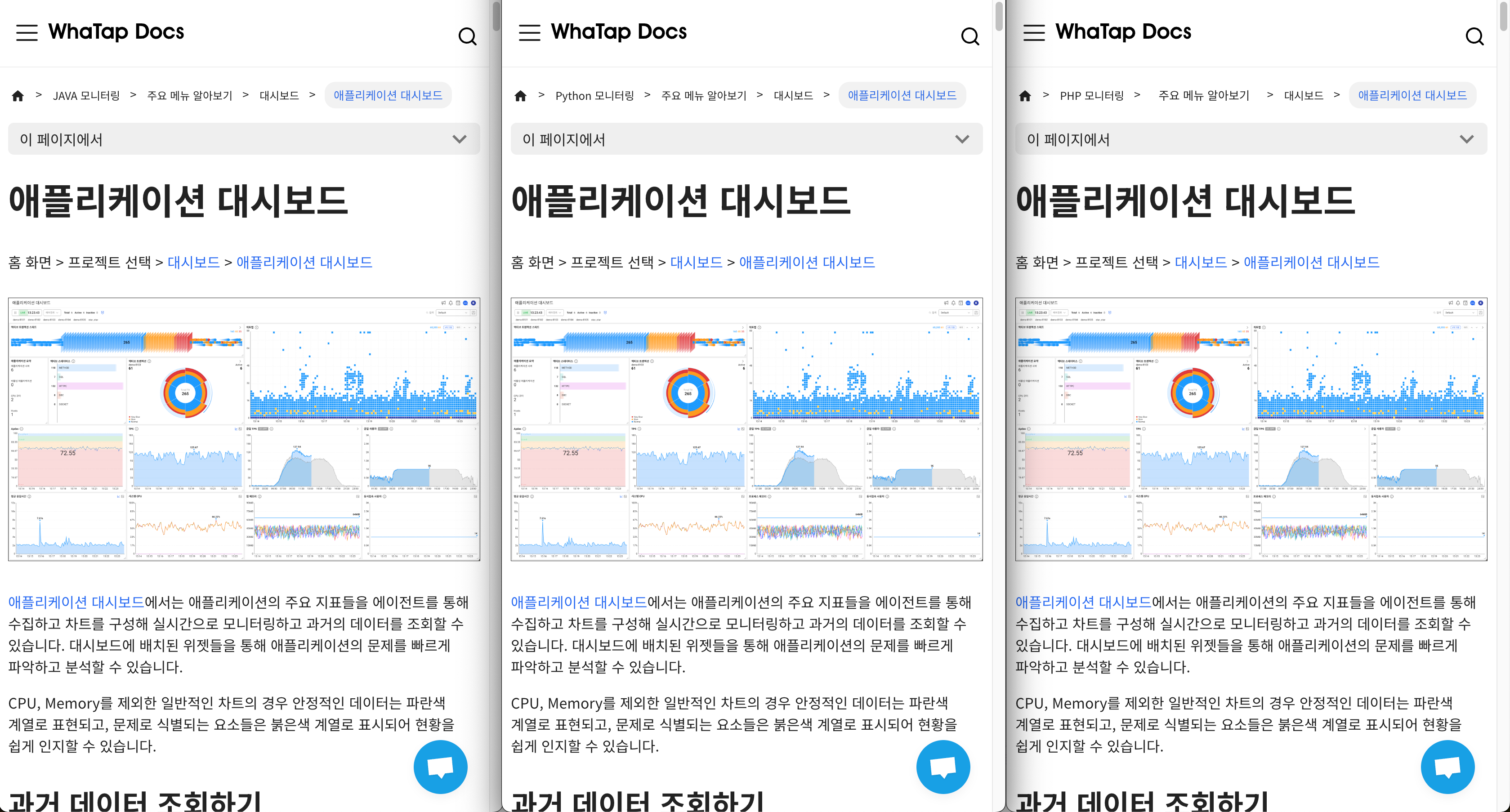
As shown in the image above, all Java, Python, and PHP documents corresponding to Watap's application product category are the result of reusing the same document.
However, some details may vary depending on the detailed product. This is the case where the Java product provides a “heap memory” widget, while the PHP product provides a “process memory” widget, as shown below.

In this way, some contents of a document are processed differently depending on the conditions Conditional processing (Conditional processing)It's called.
Conditional processing
In DITA XML, you can adjust the output differently depending on specific attributes. WTAP uses this methodology to develop and utilize components. For example, Java products provide a “heap memory” widget, and PHP products provide a “process memory” widget.
<!-- Java product -->
# Application dashboard
import HeapWidget from '. /_heap-widget.mdx ';
<HeapWidget /><!-- _heap-widget.mdx -->
<InDoc product="java">
## Heap memory
! [heap memory] (/img/apm-dashboard-heap-memory.pn)
You can check which servers are at risk by displaying the maximum memory available for each server and the current memory. You can view changes in memory usage over time in real time.
The memory line chart usually fluctuates continuously. It increases when the application server uses memory to process requests. It decreases when cleaning up memory through GC (Garbage Collection). The heap memory indicator is expressed using an average value.
:: :tip
For more information on analyzing heap memory charts, see the following links:
- [Monthly Watap: Metrics to watch for] (https://www.whatap.io/ko/blog/94/)
- [Java heap memory chart analysis: Observing the Ch.1 hip chart] (https://youtu.be/FcWfVrETWh4)
- [JAVA heap memory chart analysis: Ch.2 memory rick and hip dump analysis] (https://youtu.be/t2q5z4HHNfs)
:::
</InDoc>
<InDoc product="php">
## Process memory
! [Process memory] (/img/apm-dashboard-process-memory.png)
Shows the maximum system memory that can be used by each server plus the memory used by the specified process.
The memory line chart usually fluctuates continuously. It increases when the application server uses memory to process requests. It decreases when cleaning up memory through GC (Garbage Collection). Process memory metrics are expressed using average values.
</InDoc>
Like this inDoc You can use components to output different results depending on the product. Product Depending on the attributes, you can select the output to be displayed on the current page. herewith pages Using attributes, you can also adjust the output to vary depending on the page of the document.
inversely Xclude An additional component has been created and used, and this component is a component that can exclude content from some products. inDoc Instead of components Xclude The reason for using components inDoc Of the component Product This is to avoid situations where many attribute values need to be used.
_sample.mdx To import a file from multiple documents and exclude content inDoc To use components, do the following Product You must keep adding attributes.
<!-- _sample.mdx -->
<InDoc product="php,python,go,dotnet,mysql,...">
This content is excluded from Java products only.
</InDoc>
though Xclude If you use components, you only need to add one excluded product name as an attribute value:
<!-- _sample.mdx -->
<Xclude product="java">
This content is excluded from Java products only.
</Xclude>
This eliminated the need to create multiple identical documents, and repeated revisions were reduced to a minimum by reusing documents.
Adjusting document levels
Docusaurus lacks the degree of freedom to adjust document levels. To solve this, we developed a component for creating titles and a component for rendering the right table of contents.
inDoc, Xclude Although documents are efficiently managed using components, there was a disadvantage that the title level of the document could not be adjusted as desired. In the xml environment, the document level can be adjusted by arranging documents structurally in map units.
<map>
<title>DITA work at OASIS</title>
<topicref href="oasis-dita-technical-committees.dita> <!-- headng 1 -->
<topicref href="dita_technical_committee.dita"/><!-- headng 2 -->
<topicref href="dita_adoption_technical_committee.dita/> <!-- headng 2 -->
</topicref>
<mapref href"oasis-processes.ditamap” />
...
</map>
I'd like to adjust the document's title level based on where I add the documents I reuse, but Docusaurus didn't allow that freedom. Also, there was an inconvenience of having to separate the title from the content because an unwanted title was displayed in the table of contents level on the right.



Docusaurus did not generate a table of contents for randomly generated headings; there was only logic to parse titles written only in markdown and generate a table of contents.
To solve this problem, a new component for creating titles was created, and a new component for rendering the right table of contents was also developed and applied. title The component was developed to create the same result as Docusaurus, and the logic was changed to generate the table of contents by parsing the content rendered in html. In Docusaurus Swizzle You can extract and customize the components used by Docusaurus through CLI commands.
importWrite the document to be done as follows.
<!-- file: _heading_contents.mdx -->
<Title hashid="headings” level=</Title> {props.level} >Test heading {props.level}
This document for testing.
hashid: Enter the hash id of the heading content.
Level: Enter the level of the heading content. You can enter between 2 and 6.
in another mdx document _heading_contents.mdx If you call a document in the following way, you can output the same content at a different heading level.
import TestDoc from”. /_heading_contents.mdx “;
<TestDoc level= {2} />
<TestDoc level= {3} />
The output is shown below.

At the end...
I introduced how to efficiently manage technical documentation in WTAP by applying the DITA XML methodology in the React environment. This allows technical writers to minimally produce documents and focus on documents to provide good quality documents.
In addition, various document engineering is applied to Watap technical documentation. If you have any questions, feel free to contact the Watap Technical Writers team. too docs.whatap.io You can also send your feedback by clicking the “Feedback” button in the bottom right corner of the page.
refers
- DITAIt supports large-scale document management and conversion to various output formats, and is particularly popular in large enterprises. It is an open source that can maintain the structural consistency of documents and maximize reusability based on XML. (RaterBewriting, DITA-language)
- Docusaurusis an open source SSG engine that is relatively simple to set up and use, and is suitable for small to medium projects or software development documentation. It's written based on React and Markdown, so users familiar with web technology can easily access it. (LogRocket Blog, Docusaurus)




