.svg)
.svg)


MxDB that stores WhaTap Data
WhaTap is a performance monitoring solution for business systems with increasingly diverse and complex architectures. It must be able to collect and store a large number of monitoring metrics from various architectures in real time, as well as provide real-time insights to users. Many monitoring solutions use commercial RDBMS as a storage for metrics collected in real time, which is showing limitations in terms of speed and scalability. WhaTap has developed and uses a time series database that matches the nature of monitoring data and has the scalability and performance to accommodate data from global services. Introducing MxDB, WhaTap's own time series database.
Time Series Database
The data in WhaTap is time series data. Time series data is a series of data collected or recorded at regular time intervals. This type of data is widely used in finance, the Internet of Things (IoT), and various other areas for data analysis, monitoring, and visualization. Therefore, MxDB has the following characteristics of a time series database (TSDB).
Time-based Index Support
The typical tree-based indexes we use for fast data search do not have the power to analyze time series data coming in from all kinds of devices. MxDB stores data based on time by default, and its multiple storage structures allow it to store both numerical data that occurs regularly and text data that occurs randomly. Indexes are automatically created for temporal data, and distributed storage is possible when storing data, providing fast performance by using temporal indexes and parallel processing when data is requested.
Data Query Language Support
Perhaps the biggest reason to use a database is that it provides the SQL language to handle many different types of requests for data. MxDB provides its own query language, MXQL, to give users the flexibility to manipulate and view data. MXQL has a syntax similar to SQL, so existing database users can use it without much difficulty to create their own dashboards and notification criteria.
Support for Rollup Feature
Rollup is a feature that automatically generates statistical data that is kept separately for each minute and hour of data that is entered from moment to moment. MxDB's Tag Count Pack automatically generates 1-minute, 5-minute, and 1-hour statistical data, and automatically selects the rolled-up statistical data for viewing when viewing longer charts, so you can instantly see data over longer periods of time. You can also narrow the time range you view to automatically access detailed source data for Drill Down data analysis.
Like most time series databases, MxDB does not support transactions and data refresh operations. This is strategically done to reduce code complexity to increase processing performance and prevent data from being tampered with.
Introduction to the Architecture of MxDB
Time-based Data Partitioning
MxDB categorizes and stores data by project, date, and time, which has the following advantages.
- It is easy to expand disks without affecting the partitions that receive data, and you can save money by storing older data partitions on cheaper disks.
- Data servers can be segregated by tenant as well as storage device.
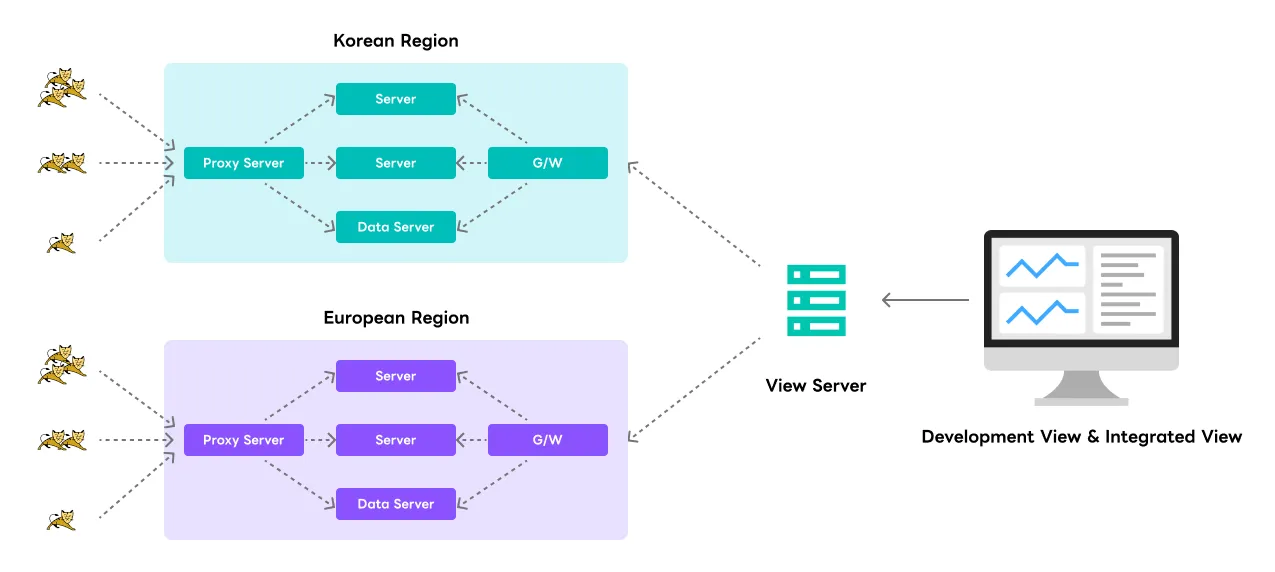
Unified User Touchpoint Server
MxDB sends collected data to a single server, even if it is distributed across multiple servers. This server is called a proxy server. When data is sent from a user or device to a single proxy server, the data is distributed to the data servers at the back end according to the settings on the proxy server. In addition to transfers, commands to manage the data servers can be performed on the proxy server, so this structure allows you to store duplexing data or perform backup or recovery commands without affecting real-time service.
Distributed Data Storage
You can distribute one data server (yard) back to multiple data servers (sharding). Distributed data is stored in a round robin fashion. Distributing data servers enables parallel processing between distributed servers, resulting in faster search speeds.
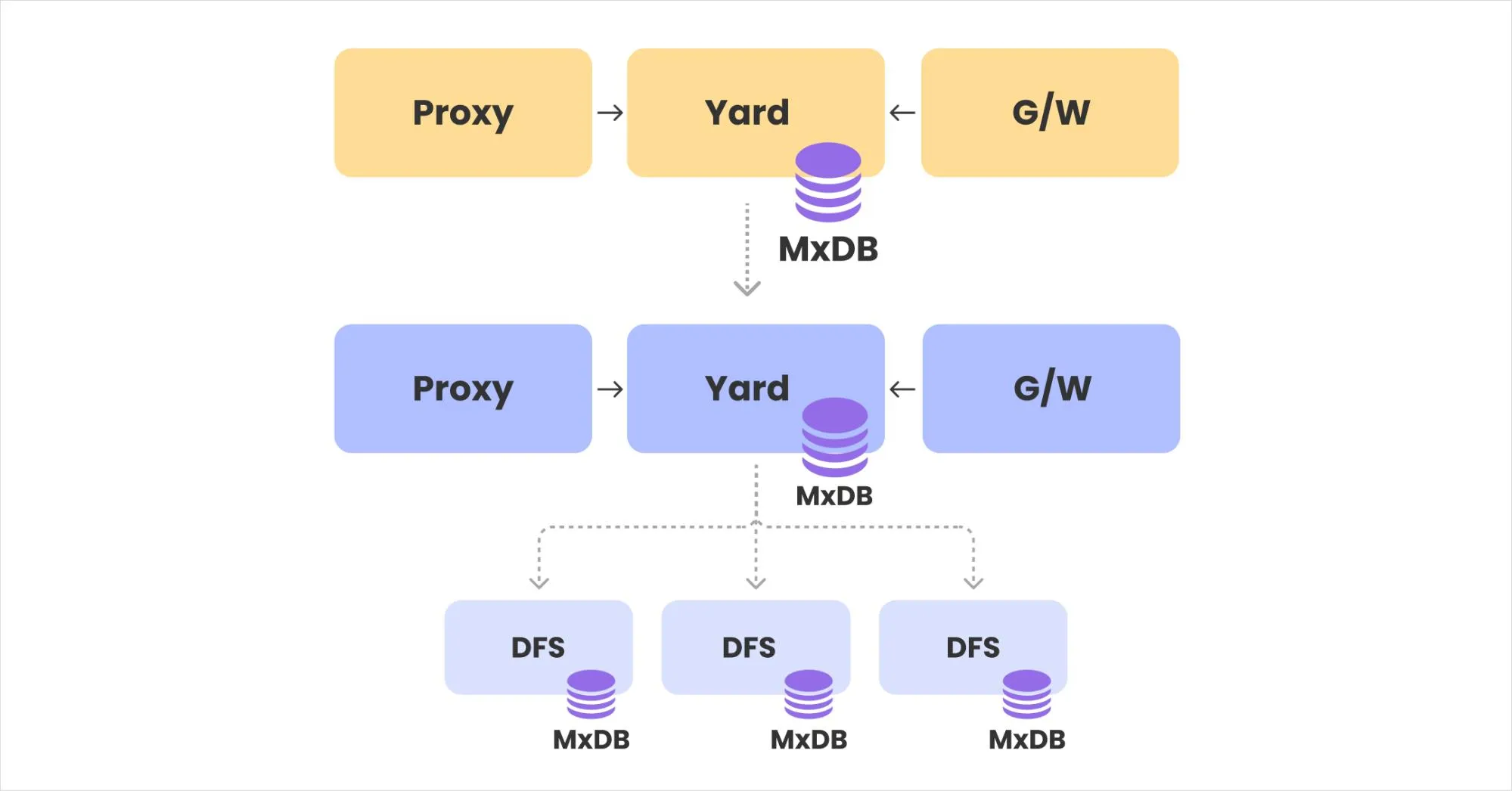
Multiplexing Structure of Data Server
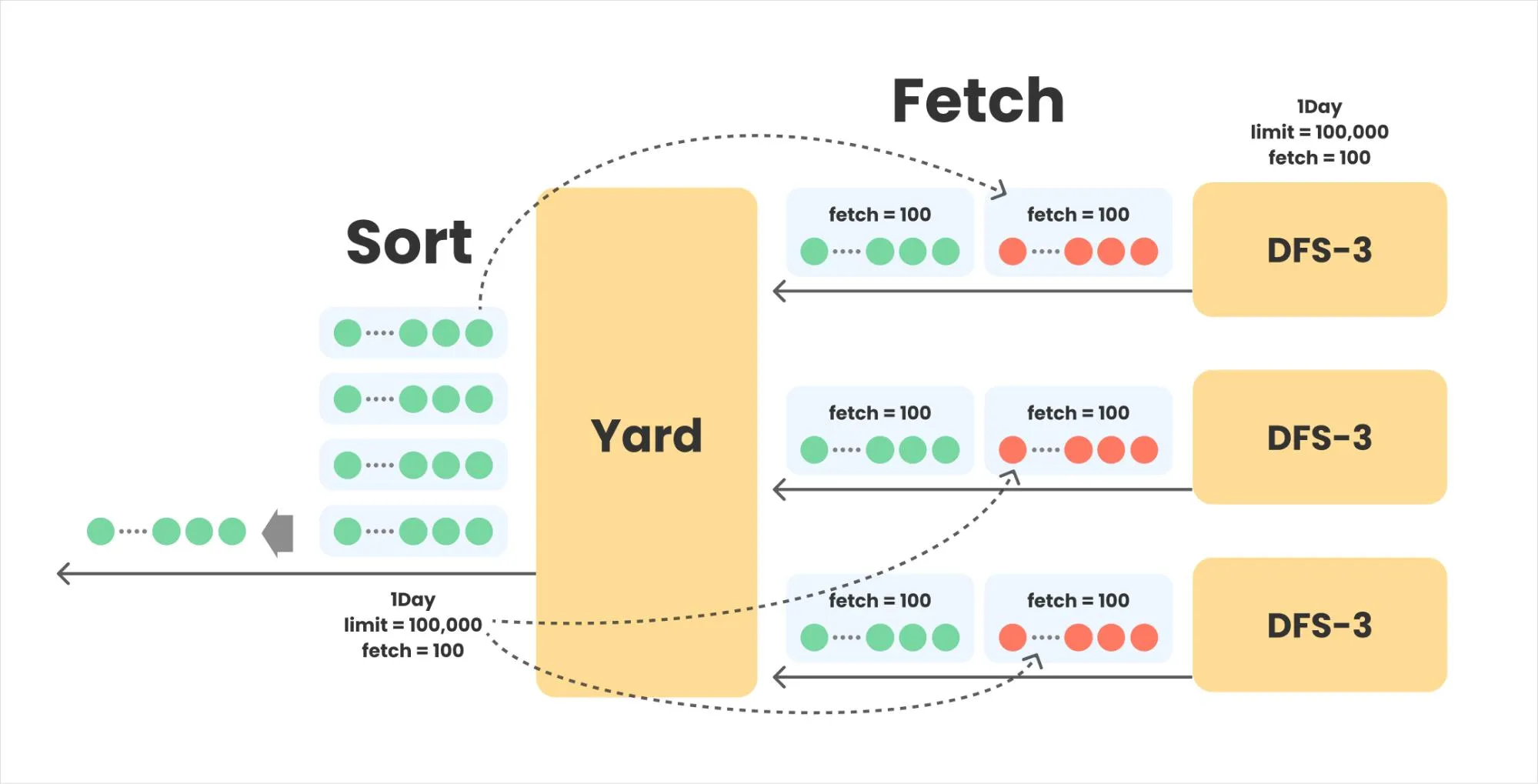
Parallelizing data fetches on multiple data servers
Data Storage Structure
MxDB also has a data storage structure like the schema, tables, and columns of a relational database. Different storage structures are designed for the types of metrics you collect to provide fast performance.
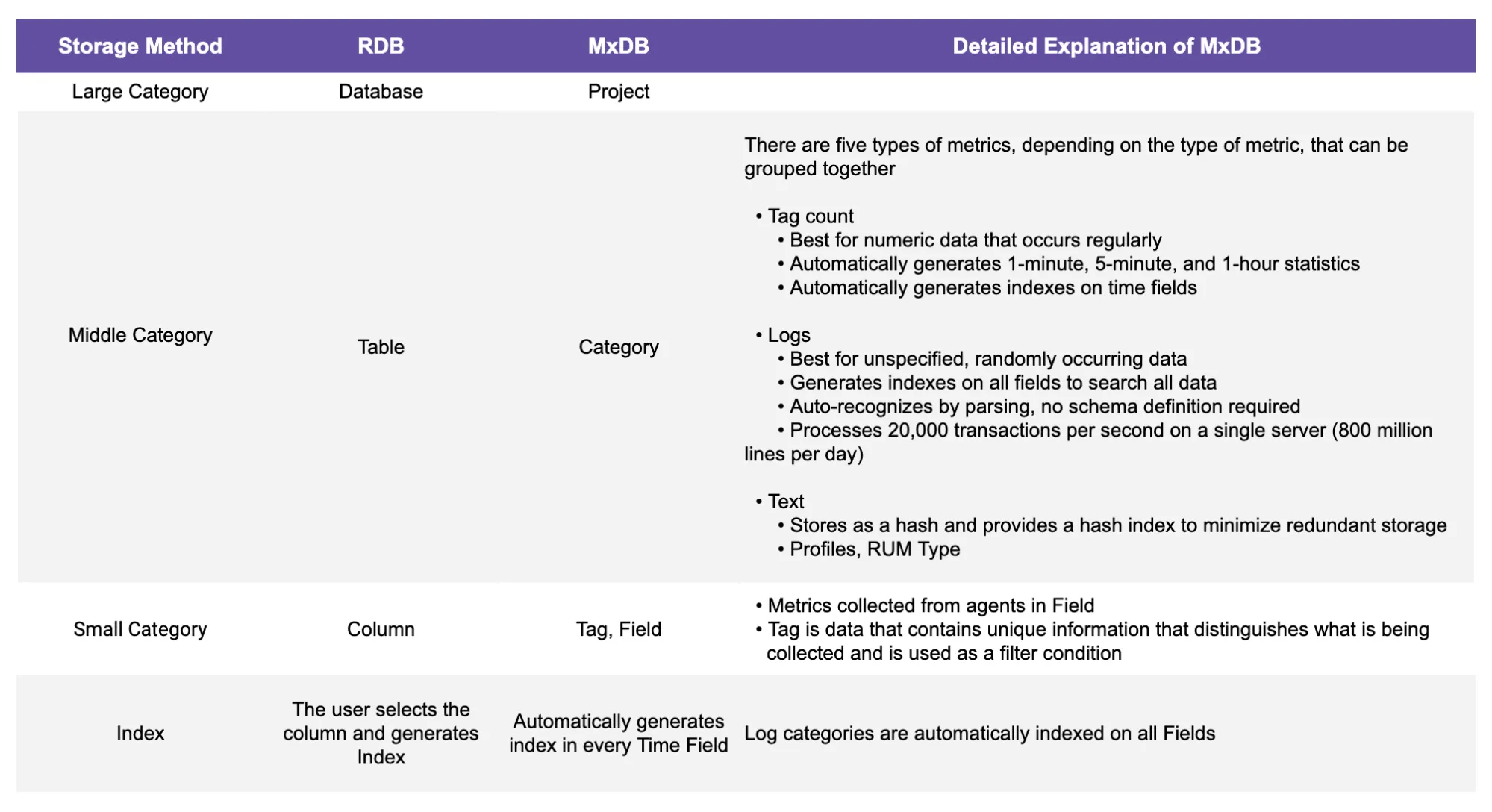
Comparison of the storage structure of RDB and MxDB
Storage Method
RDB
MxDB
Detailed Explanation of MxDB
Large Category
Database
Project
Middle Category
Table
Category
There are five types of metrics, depending on the type of metric, that can be grouped together
- Tag count
- Best for numeric data that occurs regularly
- Automatically generates 1-minute, 5-minute, and 1-hour statistics
- Automatically generates indexes on time fields
- Logs
- Best for unspecified, randomly occurring data
- Generates indexes on all fields to search all data
- Auto-recognizes by parsing, no schema definition required
- Processes 20,000 transactions per second on a single server (800 million lines per day)
- Text
- Stores as a hash and provides a hash index to minimize redundant storage
- Profiles, RUM Type
Small Category
Column
Tag, Field
- Metrics collected from agents in Field
- Tag is data that contains unique information that distinguishes what is being collected and is used as a filter condition
Index
The user selects the column and generates Index
Automatically generates index in every Time Field
Log categories are automatically indexed on all Fields
MXQL
It was developed by WhaTap as a language to view and process data stored in MxDB. It uses a syntax similar to SQL and is easy to learn with its top-down, serialized processing structure. MXQL commands are categorized into before and after LOAD. Before LOAD commands are specified as LOAD conditions, and after LOAD commands are executed to process data.
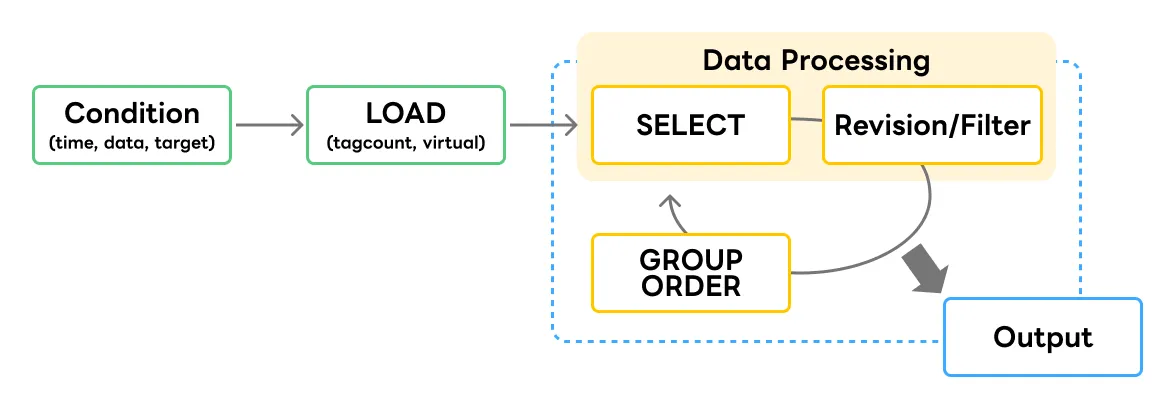
MXQL’s command structure

Difference between SQL and MXQL
Future of MxDB
MxDB was developed in 2016 to store WhaTap's monitoring data and is still adding features. Initially, it provided storage and processing features centered on numerical data, but now it is capable of collecting data and logs from tens of thousands of servers as well as processing data transmission logs from numerous applications. We look forward to competing with commercial time series databases in the age of smart devices with its fast processing structure, flexibility in architecture, and ability to accommodate client needs.




