.svg)
.svg)



If you are running a service, you have probably encountered failures at some point. In fact, every service fails. They happen for a variety of reasons, from internal factors like missed bugs to external factors like infrastructure issues, and when they do, it is important to respond quickly. Have you ever wondered how well we respond when our services fail? Today, we will introduce you to a metric that lets you see how well we respond to failures in real numbers.
Metrics to determine ability to respond to failures MTTD/MTTR/MTTF/MTBF
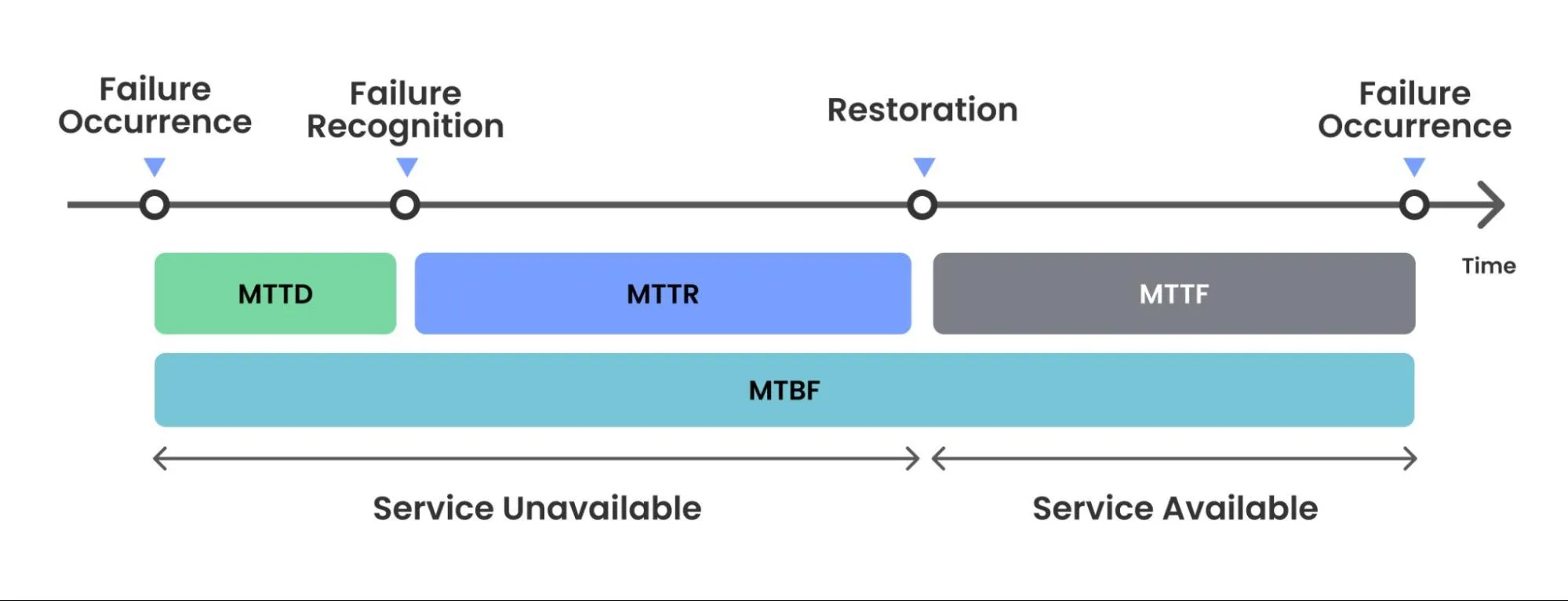
MTTD (Mean Time To Detect)
MTTD stands for Mean Time To Detect and is commonly used in software systems to measure the average time it takes to detect a service health breach or threat. It refers to the amount of time that elapses between the initial degradation of a system or network and the moment your team becomes aware of the failure or incident. MTTD is an important metric to track because the sooner you detect a failure, the sooner you can take action to contain the threat and minimize damage.
MTTD is typically measured in hours or days and can assess the overall efficiency of an organization's operations. You want to ensure that your operations are effective at detecting performance degradation and minimizing downtime. You use MTTD to measure the average time it takes to detect a performance degradation or incident.
MTTR (Mean Time To Repair)
MTTR stands for Mean Time To Repair and is a metric used to measure the average time it takes to repair a failed system and restore it to normal operation. MTTR is often used in engineering and maintenance to evaluate the efficiency of repair processes and identify opportunities for improvement. MTTR is an important metric to track because it helps you identify areas for improvement in your maintenance processes, such as reducing downtime and improving response times. MTTR can also be used in conjunction with other reliability metrics, such as MTBF, to get a more complete picture of reliability and maintenance requirements.
MTTR is typically calculated by dividing the total downtime due to failures by the number of repair events. The resulting value represents the average time required to repair a system or component. If you want to ensure that your service is always up and running to keep your customers happy, use MTTR as a metric to measure the average time it takes to repair a failed system or component and restore it to normal operation.
MTTF (Mean Time To Failure)
MTTF stands for Mean Time To Failure and is a reliability metric used to estimate the average total time a product or system can operate before it fails. The more reliable the system, the longer the MTTF. MTTF is often used in engineering and product development to assess the expected lifespan of a component or system and can help inform decisions about maintenance schedules, replacement strategies, and overall design.
MTTF is typically calculated by running a series of tests or simulations on a product or system and recording the time until failure for each instance. The MTTF is then calculated as the average of all recorded failure times. For example, if your organization had four computers and each computer lasted 10 months, 4 months, 16 months, and 3 months, your MTTF would be: (10 + 4 + 16 + 3)/4 = 8.25 months, which means you have an MTTF of 8.25 months.
MTBF (Mean Time Between Failure)
MTBF stands for Mean Time Between Failure and is a reliability metric used to estimate the average time a product or system operates between two consecutive failures. The longer this MTBF is, the higher the service reliability and normal operating performance. MTBF is often used in engineering and product development to evaluate the reliability of a component or system and to determine the optimal maintenance schedule. MTBF is calculated by dividing the total operating time of a product or system by the number of failures that occurred during that time. The resulting value represents the average time between two consecutive failures.
At the end of the day, organizations should be thinking about how to increase MTTF as much as possible and how to decrease MTTR even further.
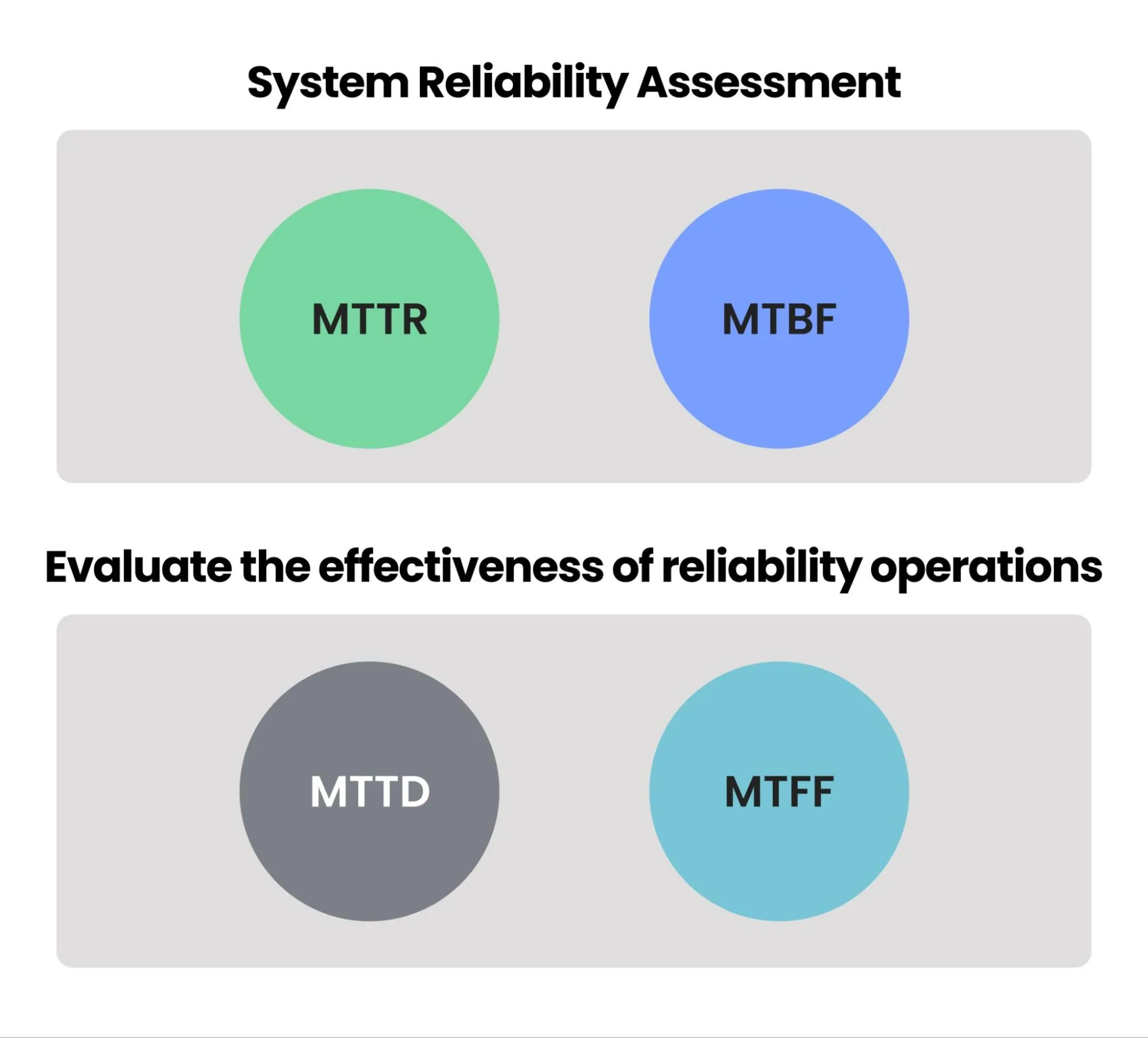
How to evaluate the reliability of a system and the effectiveness of reliability operations
MTBF, MTTR, MTTD, and MTTF are related but measure different aspects of the reliability and availability of a system or component. However, when used together, they provide a comprehensive view of a system's performance, diagnostics, and maintenance requirements.
For example, MTBF and MTTR are often used together when evaluating the reliability of a system. MTBF estimates the expected time between two consecutive failures, while MTTR estimates the time it takes to repair a failed component. By comparing MTBF and MTTR, engineers can determine if the repair time is reasonable compared to the expected time between failures.
MTTD and MTTF are also often used to evaluate the effectiveness of reliability operations. MTTD estimates the average time it takes to detect a degradation or incident, while MTTF estimates the average time between incidents. By tracking MTTD and MTTF, SRE and DevOps teams can identify areas for improvement in their detection and response processes.
The war on failure, why we must monitor
Taken together, these four metrics provide a more complete picture of the reliability, availability, and maintainability of a system or component. Organizations can use these metrics to optimize maintenance schedules, identify opportunities for improvement, determine incident metrics, and make data-driven decisions about design and maintenance strategies.
Many organizations want to fight fewer battles with failures and spend more time focusing on customers, which is why engineers can leverage strategic observability key performance indicators to get to the root cause of system outages faster and reduce the time it takes to resolve them. While it is commonly thought that receiving more failure notifications means fighting more battles, the reality is that resolving issues faster directly reduces notification fatigue.
Understanding key performance indicators for system reliability is critical to ensuring digital resilience. By tracking these metrics, organizations can improve response times, reduce notification fatigue, and provide a better customer experience. However, it is hard to be sure that all services are running well every time, which is why we need to use monitoring services.
WhaTap is a monitoring platform that lets you detect failures in real time. You can view application, server, DB, browser, Kubernetes, logs, and even cloud network performance on one platform. Try WhaTap Monitoring today with a 15-day free trial!




