.svg)
.svg)


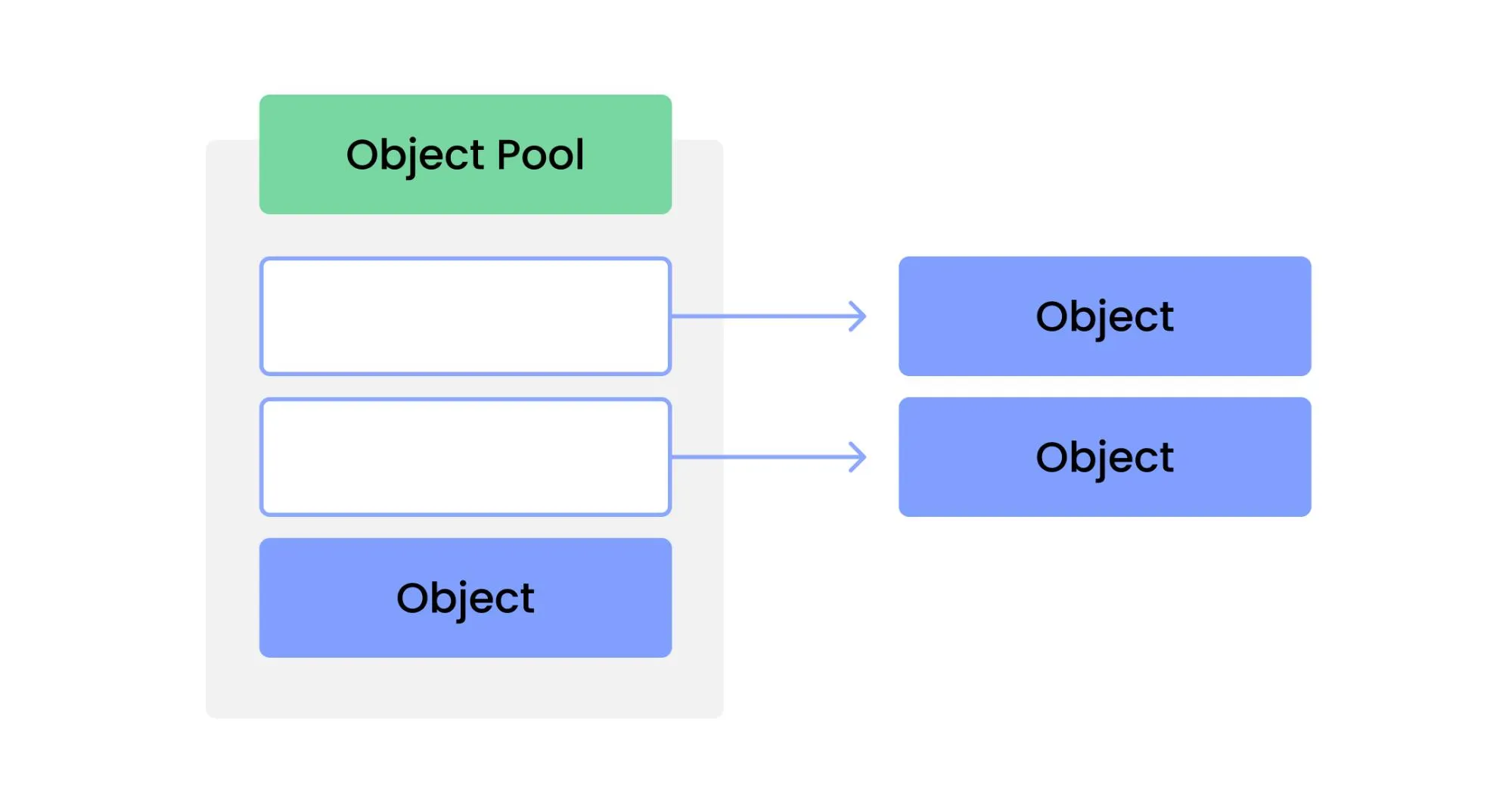
When processing a series of fast transactions, you may encounter a situation where the imbalance between the speed of object creation and the GC execution cycle results in high memory and CPU usage. In this article, we would like to share the results of validating the idea of using Object Pool in this situation.
Test results and evaluation
Measuring CPU and memory usage
On the left is the result of applying the object pool, and on the right is the result of creating and using objects as needed.
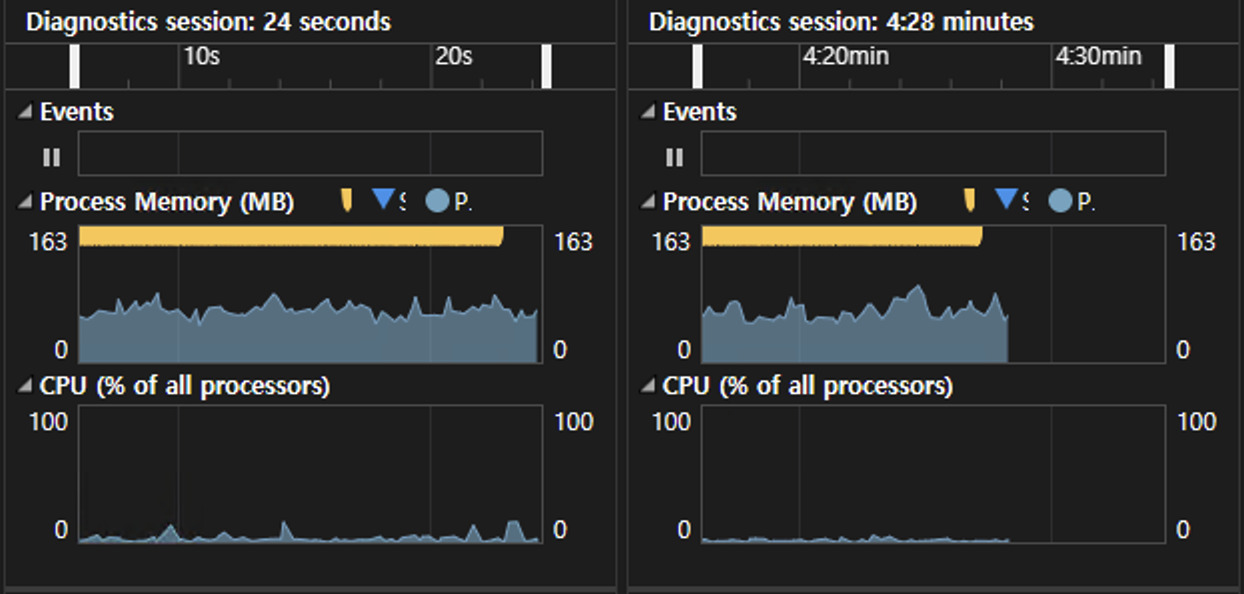
- We did not see any noticeable difference in memory usage.
- Without the object pool, we measured a slightly larger change in memory usage as objects are returned each time the GC runs.
- CPU usage was higher with object pools, and the change in usage was also larger.
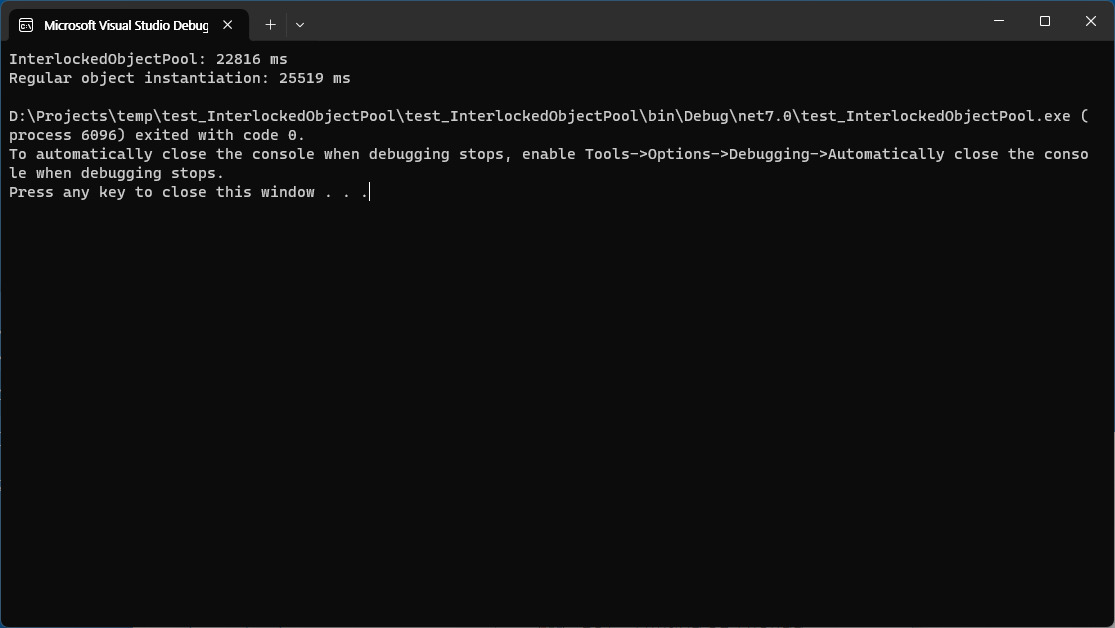
Test execution time measurements
In terms of test execution time, we measured that using a memory pool is slightly faster.
Evaluation
We found that the object pool used in the test uses a little more CPU, with no significant difference in execution time.
The test conditions were simple, so it is hard to conclude anything based on these results, but in general, there does not seem to be a significant advantage. However, the performance advantage can change depending on the buffer size and number of threads in the memory pool, and the complexity of how objects are initialized or freed can further emphasize the benefits of object pools.
The class code for an object that is the target of an object pool is as simple as the following.
public class Step : IDisposable
{
private bool _disposed = false;
~Step()
{
Dispose(false);
}
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (_disposed) return;
_disposed = true;
if (disposing)
{
// Dispose managed state (managed objects).
}
}
public Step Parent { get; }
public long TraceId { get; set; }
public DateTimeOffset StartTime { get; }
public TimeSpan Duration { get; set; }
public string ResourceName { get; set; }
}
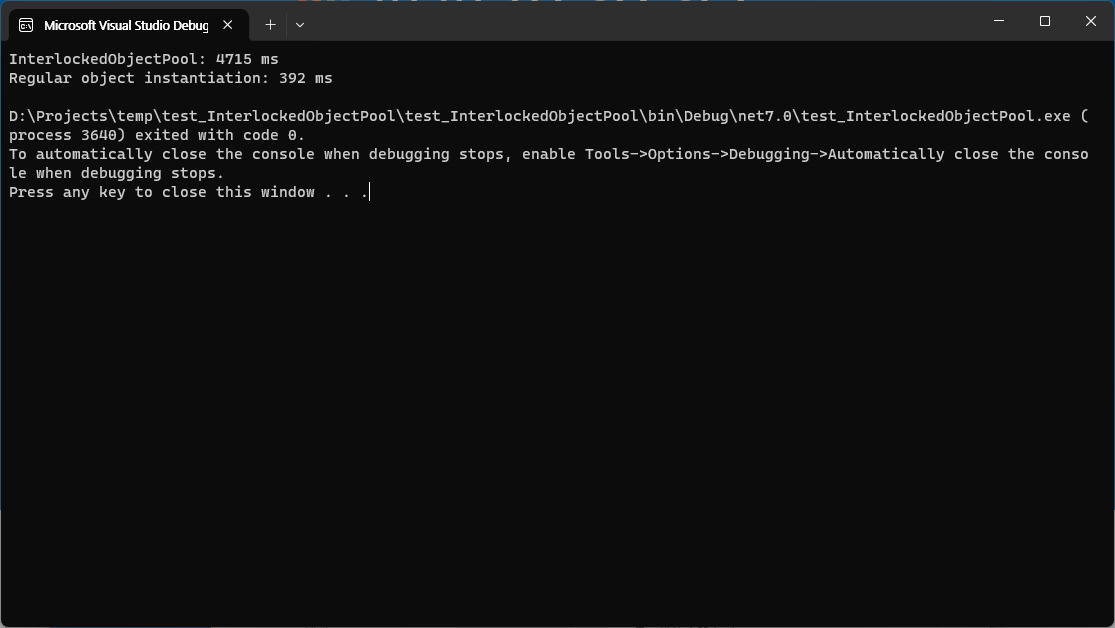
Below are the runtime results when we made the Step class simpler by not inheriting from IDisposable.
You can see that the object pool's execution time is about 12 times longer, making the loss even worse.
The code for the Step class used in the above test looks like the following.
public class Step
{
public Step Parent { get; }
public long TraceId { get; set; }
public DateTimeOffset StartTime { get; }
public TimeSpan Duration { get; set; }
public string ResourceName { get; set; }
}
Exploring the Code of Memory Pools
LazyRelease class
When implementing memory pools in a multithreaded environment, using locks can have a negative impact on performance. Therefore, we have implemented memory pools using interlocked operations instead of locks. The basic algorithm for this is an overwriteable ring buffer with no Full state. This allows us to implement a thread-safe data structure without locks by using interlocked operations, since we only need to increment the index pointing to the current location.
LazyRelease only has a Release() method, and objects passed to it are not destroyed immediately, but are kept for as long as the size of the ring buffer. Hence the name LazyRelease, which means that they are deleted later.
public class LazyRelease
{
private const uint Capacity = 1 << 16; // 2^16
private readonly T[] buffer = new T[Capacity];
private int tail = 0;
public T Release(T value)
{
int index = Interlocked.Increment(ref tail) & 0xFFFF;
T oldItem = buffer[index];
buffer[index] = value;
return oldItem;
}
}
As the index grows, we need to cycle back to the beginning so that the index does not overflow. We do this by making sure that the value before the change has not been changed by another thread, as shown in the code below.
if (index > Capacity)
{
Interlocked.CompareExchange(ref tail, index % Capacity, index);
}
The problem is that Interlocked is just as CPU-harassing as Lock, if not more so. So in the LazyRelease class, we use a value for Capacity that is divisible by the maximum value of index, so that we do not have to worry about overflow.
We have also been able to save even more performance by replacing the % operator with the & operator instead of the more CPU-harassing % operator.
Interlocked Object Pool
Interlocked Object Pool is a class that implements a real-world object pool. It provides the ability for the GetOrCreate() method to return a new object. If it can fetch from the memory pool, it returns the object directly, but if it fails, it creates a new object and returns it.
This can fail even if there are enough objects stored in the memory pool, because if you want to handle this correctly, you will eventually need to lock. If you lock, the cost of performance issues can outweigh the benefits of using a memory pool, which is why we use this method of allowing failures.
public class InterlockedObjectPool
{
private LazyRelease _buffer = new LazyRelease();
public Step GetOrCreate()
{
Step newObject = null;
var old = _buffer.Release(null);




