.svg)
.svg)


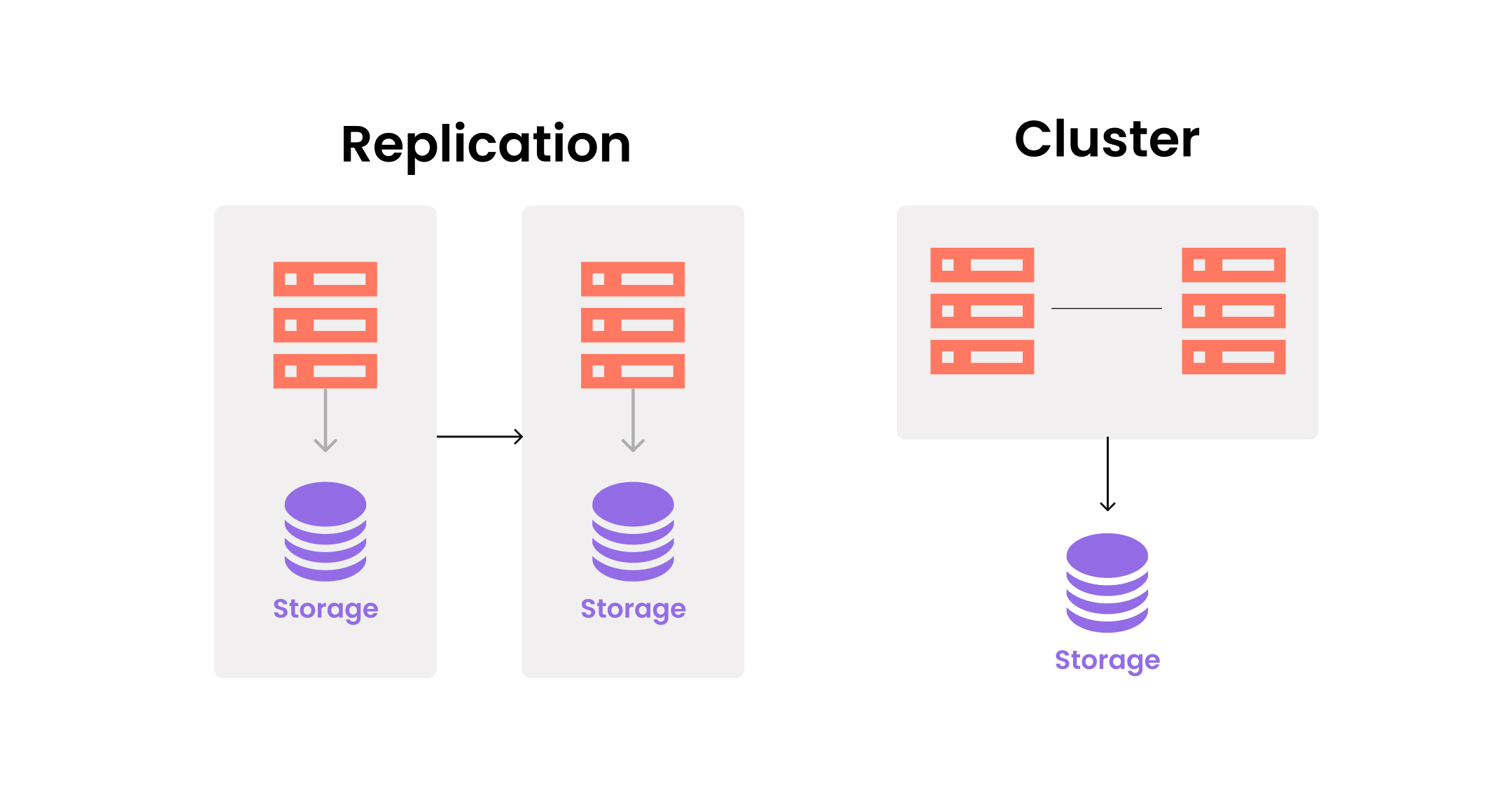
How databases are organized
A database is basically composed of a database server and storage where the database is stored in a 1:1 ratio.
However, as you run your service, there are times when the DB server cannot accommodate transactions or the data stored in the DB storage becomes corrupted. Clustering and replication are DB server and DB storage configurations designed to solve these problems.
In this content, I will explain clustering and replication from the perspective of a non-developer, someone who is just starting to learn about development.
Clustering two or more servers as a single unit
In databases, clustering is how multiple DB servers share a single piece of storage. Database clustering is divided into Active - Active and Active - Stand by methods.
The advantage of the Active-Active method is that even if one DB server goes down, the other DB server can continue to operate. Also, because there are two servers, the CPU, memory, etc. of the DB server can be doubled, so it can more than double the performance in terms of availability. However, the Active-Active method can be a bottleneck because it shares one storage, and it can be costly because it runs two servers at the same time.
Active - Stand by is having one DB server in the Active state and the other DB server in the Stand by state. If the Active DB server fails, the Stand by server acts as the Active server. The advantage of Active - Stand by is lower operating costs.
Since the Stand by server does not usually operate, you only need to pay for the cost of an Active DB server. On the other hand, because the Stand by server does not usually operate, it takes tens of seconds to tens of minutes to switch to the Active server.
Replication which copies database storage
Replication is intended to minimize data loss by replicating storage in case of data loss due to various issues. Replication is built in a vertical structure with a source (master) and a replica (slave). There are four main purposes for deploying replication.
- Scale-out: Improving performance by increasing the number of servers to reduce the load on a sudden increase in traffic.
- Backup: Backing up data on Replica without affecting the Source data due to possible query corruption during the backup process.
- Data analytics: You can perform data analytics on the Slave without affecting the performance of the Master server.
- Geo-distribution of data: Even if you are physically distant from the Source server, you can still get responses from the Replica server and get faster speeds.
Simple backup is a method that divides two or more database servers and storage into Source (Master) and Replica (Slave) to store the same data. The distributed method does not utilize the Slave DB for backup, so the Slave DB is used as a load balancing method.
Utilizing Slave for backup involves dividing two or more database servers and storage into Master and Slave to synchronize and store the same data. Another way to utilize Slave for reads is to configure Select operations to be performed on the Slave to reduce the load on the Master. Because Select operations take time, it is hard to do other things, so you can offload them to the Slave, which can help improve performance.
The disadvantages of replication include the need to maintain separate version control for Master and Slave because they run on different servers. Also, you cannot guarantee the accuracy of the data: if the Slave cannot keep up with the Master's data processing speed, the two might not match. Finally, you might not see any performance improvements with a replicated configuration.
Scale your databases with a plan to match your services
Clustering and replication are context-sensitive ways to scale your database, and you do not want to scale your database without a plan. If you plan to scale your database for your services, you will be able to provide better quality service to your clients.




