.svg)


안녕하세요! 2024년 마지막 레터입니다. 2024년 한 해도 정말 고생 많으셨고, 2025년에는 새로운 마음으로 더욱 의미 있고 유익한 한 해를 시작하길 진심으로 바라겠습니다. 저희 와탭 역시 2025년에도 신규 업데이트 소식과 다양한 콘텐츠를 준비하고 있으니 많은 기대와 관심 부탁드립니다. 미리 새해 복 많이 받으세요! 🙇♂️🙇♀️
이번 호에서는 최근 발생한 챗GPT 장애 이슈에 대해 다뤄보려고 합니다.
2024년 12월 12일, 한국 시간으로 오전 8시 16분부터 오후 12시 38분까지 챗GPT를 포함한 오픈AI의 서비스인 Sora, API 등에 장애가 발생했습니다. 장애는 약 4시간 20분만에 복구가 되었지만, 전 세계적으로 많은 사용자를 보유한 서비스인 만큼 해당 사건은 연일 화제가 되었습니다.
오픈AI의 보고에 따르면 장애는 쿠버네티스 컨트롤 플레인 과부하로 인해 발생하였습니다. 대규모 클러스터 환경에서 과도하게 발생한 쿠버네티스 API 요청이 컨트롤 플레인에 과부하를 일으킨 것이죠. 오늘 레터에서는 이번 챗GPT 사건의 자세한 원인부터 장애의 핵심 요인이었던 컨트롤 플레인에 대한 내용까지 쉽게 이해할 수 있도록 준비했습니다.
다음과 같은 순서로 글이 전개됩니다!
1️⃣ 챗GPT 장애가 발생하다!
2️⃣ 챗GPT 장애, 원인은 무엇이었을까?
3️⃣ 컨트롤 플레인 모니터링의 중요성!
4️⃣ 와탭의 컨트롤 플레인 모니터링
5️⃣ 결론, 그리고 교훈
챗GPT 장애가 발생하다!
2024년 12월 12일 오전 9시, 평소처럼 출근하여 업무를 시작했습니다.
그날도 여느 때와 다름 없이 챗GPT에 업무 관련 정보를 서칭해달라고 요청을 남겼습니다. 이제는 일상이 되어버린 챗GPT, 이 서비스 덕분에 업무 효율성이 상당 부분 개선되었습니다.
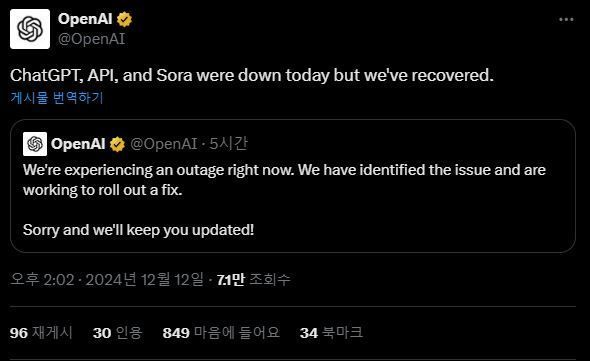
그런데 문제가 발생했습니다. 평소 몇 초 안에 명쾌한 답변을 제공하던 챗GPT가 제대로 동작하지 않았죠. 몇 번을 다시 시도해봐도 돌아온 건 다음과 같은 메시지였습니다.
"Chat GPT is currently unavailable.
Status: Identified - We have identified the issue and are working to roll out a fix"
네 맞습니다. 챗GPT 서비스에 장애가 발생한 것이었습니다.
그후 이 장애는 약 4시간 동안 지속되었습니다. 챗GPT 서비스 장애 직후 관련 커뮤니티 채팅방은 이미 난리였습니다. 국내에도 챗GPT가 다수의 고객을 확보하고 있음을 단번에 알 수 있는 모습이었으며, 심지어 유료 사용자(월 약 2만 8천원)도 꽤 많이 있다는 사실을 알게 되었죠.
실제로 찾아보니 2024년 10월 기준 국내 챗GPT 월간 활성 사용자 수(MAU)는 약 258만 명이라고 합니다. (출처: 뉴시스, “챗GPT, 4시간 이상 접속 장애…유료 가입자 보상받을까(링크)”)
이 장애는 오후 12시 40분이 되어서야 복구되었습니다. 이후 챗GPT를 만든 오픈AI는 공식 웹사이트를 통해 해당 장애에 대한 보고서를 발표했는데요. 보고서에 따르면 12월 12일 오픈 AI의 챗GPT, Sora 등 생성형 인공지능(AI) 서비스가 약 4시간 동안 중단 또는 지연 현상을 보였다고 전합니다.
통계에 따르면 2024년 12월 기준으로 전 세계 챗GPT의 주간 활성 사용자 수(WAU)는 약 3억 명에 달한다고 합니다. 이 정도 사용자를 보유한 서비스에서 4시간 장애를 가진다는 건 매출 손실뿐만 아니라 서비스 신뢰도 측면에서도 큰 손실을 가져옵니다.
오픈AI가 장애에 신속하게 대응을 했을지 몰라도 이로 인해 고객들이 환불을 요청하거나, 서비스 신뢰도 저하로 인해 장기적인 매출 감소가 발생할 수 있겠죠.
그렇다면, 우리는 이러한 치명적인 장애가 발생하게 된 원인을 살펴볼 필요가 있습니다. 주간 3억 명 유저가 사용하는 서비스를 마비시킨 장애의 원인은 무엇이었을까요?
챗GPT 장애, 원인은 무엇이었을까?
이번 장애의 근본 원인은 대규모 클러스터 환경에서 쿠버네티스 API 서버에 과도한 부하를 발생시킨 새로운 텔레메트리 서비스 적용입니다. 이로 인해 컨트롤 플레인이 정상적인 처리를 하지 못했고, 결국 내부 DNS 처리 실패로 이어지면서 시스템 전체가 영향을 받게 된 것입니다.
오픈AI가 발표한 공식 보고서(링크)에 따르면, 오픈AI는 전세계 수많은 사용자를 대상으로 한 AI 서비스 제공을 위해 쿠버네티스를 사용하고 있는데요. 쿠버네티스는 내부적으로 컨트롤 플레인(Control Plane)과 데이터 플레인(Data Plane)으로 구성됩니다. 컨트롤 플레인은 쿠버네티스 시스템의 핵심 관리 역할을, 데이터 플레인은 실제 애플리케이션 워크로드를 처리하는 역할을 맡고 있습니다.

최근 오픈AI는 클러스터의 상태를 더욱 정밀하게 모니터링하기 위해 새로운 텔레메트리 서비스를 적용했습니다. 물론, 하루 전에는 스테이징 환경에서의 테스트를 완료했다고 합니다. 하지만, 장애 당일 스테이징 클러스터보다 훨씬 큰 규모인 실 환경에 새로운 텔레메트리를 적용하자 예상치를 넘어서는 과도한 쿠버네티스 API 요청이 발생하였고, 그로 인해 컨트롤 플레인이 마비되었습니다.
이어 컨트롤 플레인의 마비는 쿠버네티스 내부 DNS 정보 갱신 이슈를 유발하였고, 결국 DNS 정보를 사용하는 워크로드 처리에 실패하면서 대형 장애로 번진 것입니다.
장애 발생 후 오픈AI는 신속하게 대응 전략을 수립했습니다. 그리고 전체 클러스터의 크기를 줄여 API 부하량을 감소시킴과 동시에 쿠버네티스 API 서버를 확장하여 다행히 서비스를 정상 복구하였습니다.
컨트롤 플레인 모니터링의 중요성!
챗GPT 장애의 주요 원인은 컨트롤 플레인의 과부하였습니다. 컨트롤 플레인은 쿠버네티스 클러스터의 두뇌와 같은 존재로 스케줄링, 상태 저장, 리소스 할당 등 클러스터 전반의 관리를 위한 핵심적인 역할을 합니다.
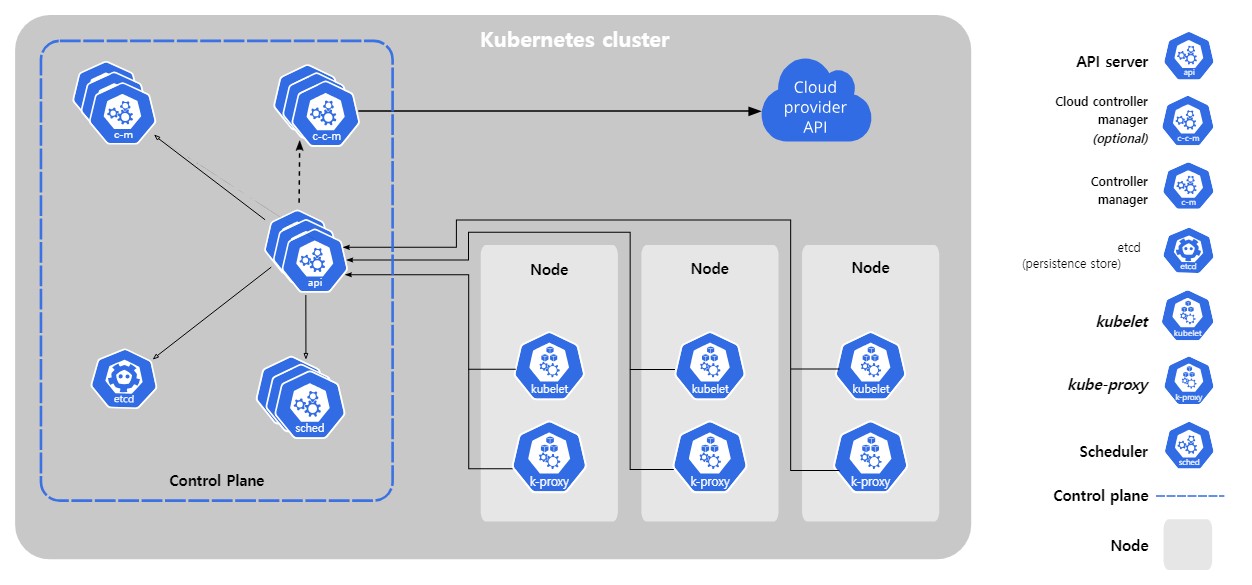
하지만, 많은 사용자들이 쿠버네티스의 견고한 설계를 과신하거나 워크로드 모니터링에만 집중한 나머지 컨트롤 플레인 모니터링의 중요성을 간과하는 경우가 많습니다.
실제 와탭 사용자 중에도 컨트롤 플레인 모니터링이 왜 필요한지 문의할 때가 있습니다. 특히 EKS, AKS와 같은 관리형 쿠버네티스 서비스를 사용하면 컨트롤 플레인에 대해서는 신경쓰지 않아도 된다고 생각하기 때문이죠.
그러나 이러한 이유로 쿠버네티스 운영 중 컨트롤 플레인을 방치하게 되면 컨트롤 플레인에 과부하가 걸리는 상황을 놓치게 되고, 결국 쿠버네티스 전체의 장애를 맞이할 수 있습니다. 와탭은 이러한 상황을 인식하여 컨트롤 플레인 모니터링을 통해 클러스터의 안정성을 유지하는 데 필요한 기능을 제공하고 있습니다.
와탭의 컨트롤 플레인 모니터링
와탭은 사용자들이 쉽고 빠르게 컨트롤 플레인 모니터링을 할 수 있도록 전용 대시보드와 알림 기능을 제공합니다.
쿠버네티스의 모든 구성요소들로부터 인입된 API 요청을 처리하는 kube-apiserver의 응답 시간, 처리량, 요청 실패 등을 추적함으로써 클러스터의 가용성을 확보할 수 있습니다. 또한, 컨트롤 플레인 관련 사전정의 알림을 템플릿 형태로 제공하여 문제 상황을 최대한 빨리 감지할 수 있도록 합니다.
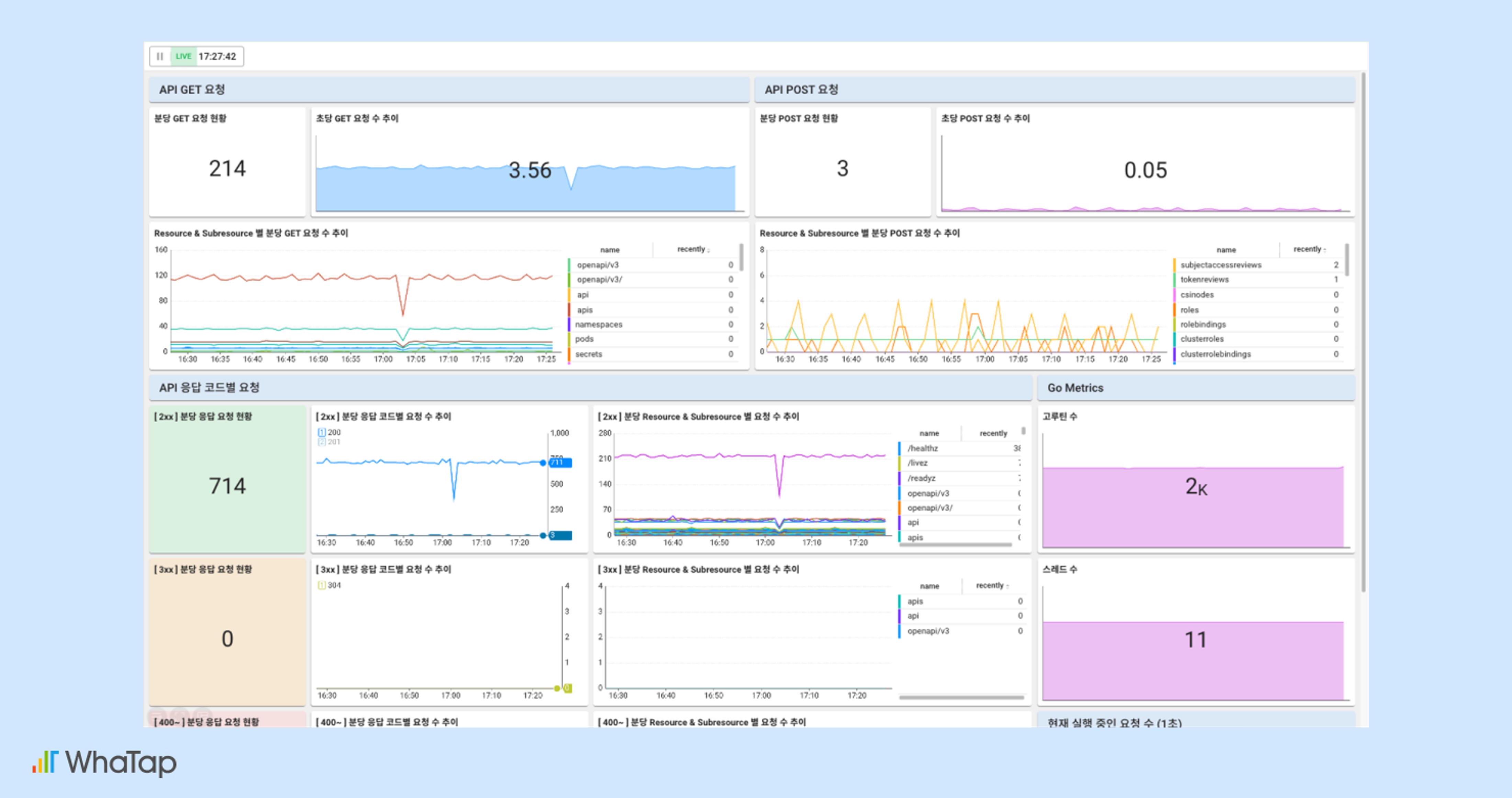
kube-apiserver 대시보드 관련 자세한 내용은 와탭의 kube-apiserver 문서(링크)에서 확인해볼 수 있습니다.
또한, 쿠버네티스 환경에서 클러스터의 핵심 메타 정보 및 상태 정보를 저장하는 etcd 관점의 대시보드도 제공합니다. 저장소인 etcd가 사용하는 리소스, 로그, commit 및 apply 횟수, 리더 변경 이력 등을 확인하여 etcd 성능과 안정성을 모니터링하고, 장애 발생 시 원인을 분석할 수 있습니다.
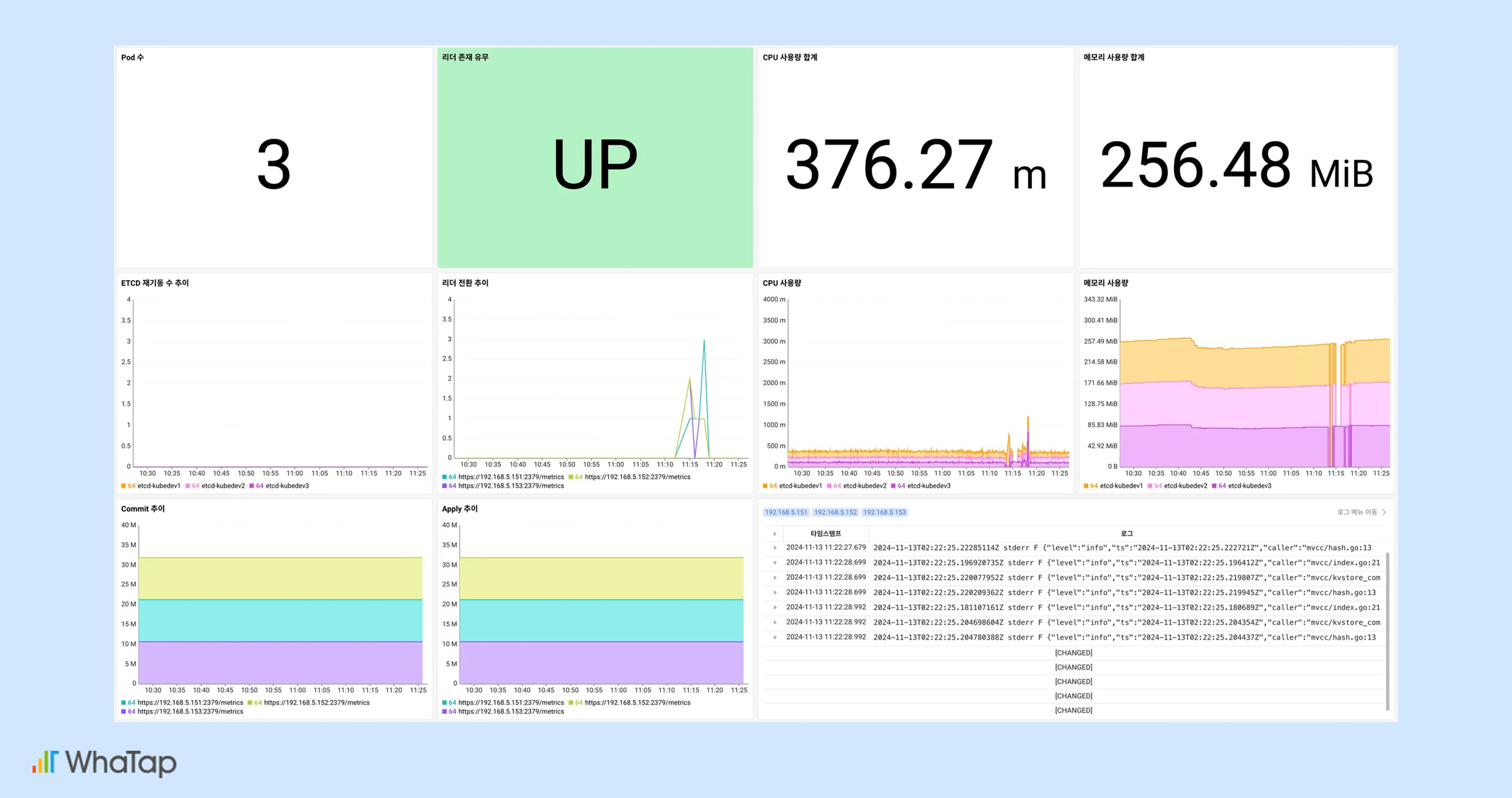
etcd 대시보드 관련 자세한 내용은 와탭의 etcd 대시보드 문서(링크)에서 확인이 가능합니다.
와탭이 선정한 컨트롤 플레인 내부의 핵심 지표와 연관 성능 지표로 구성된 대시보드를 활용한다면, 사용자는 한눈에 컨트롤 플레인의 상태를 파악하여 실시간 추이와 문제의 원인을 분석하고, 객관적인 데이터를 기반으로 리소스 확장, 성능 최적화 등의 의사 결정을 내릴 수 있습니다.
결론, 그리고 교훈
이번 챗GPT 장애 사례는 컨트롤 플레인 모니터링의 중요성을 보여줍니다. 쿠버네티스 클러스터에서 컨트롤 플레인은 워크로드 스케줄링, 리소스 할당, 상태 관리 등의 관리 역할을 담당하지만, 만약 과부하가 발생하면 데이터 플레인과 전체 서비스에 치명적인 영향을 미칠 수 있습니다.
오픈AI는 새로운 텔레메트리 서비스 도입 후 예기치 못한 API 요청 증가로 컨트롤 플레인이 마비되었고, DNS 서비스 검색 실패가 이어지며 서비스 중단 사태를 겪었습니다. 이 사례는 대규모 클러스터 환경에서 컨트롤 플레인 상태를 실시간으로 모니터링하고 문제를 사전에 감지하는 체계가 필수적임을 보여줍니다.
컨트롤 플레인의 안정성을 확보하는 방법 중 하나는 와탭의 컨트롤 플레인 모니터링을 통해 kube-apiserver의 API 요청 처리량, 응답 시간, 실패율과 같은 주요 지표를 추적하고, etcd의 상태와 리더 선출 과정을 모니터링하는 것입니다. 이를 통해 성능 병목을 조기에 발견하고 문제를 신속히 해결할 수 있죠.
쿠버네티스 환경으로 운영하는 많은 기업들이 컨트롤 플레인의 중요성을 알고, 이를 모니터링하며 안정적인 서비스 운영을 해나가길 바라면서 이 글을 마칩니다.
오늘 다룬 주제(=쿠버네티스 컨트롤 플레인 모니터링)에 대한 여러분의 의견이나 궁금한 점이 있으시면 여기에(링크) 남겨주세요. 2025년 1월, 새로운 주제와 함께 찾아오겠습니다!
긴글 끝까지 읽어주셔서 감사합니다. 🙏








